hadoop day 1 (HDFS、YARN-HA)
目的
透過 zookeeper 針對 HDFS 的 namenode 及 Yarn 的 resourcemanager 的 High Availability 機制.
- 3 台架構
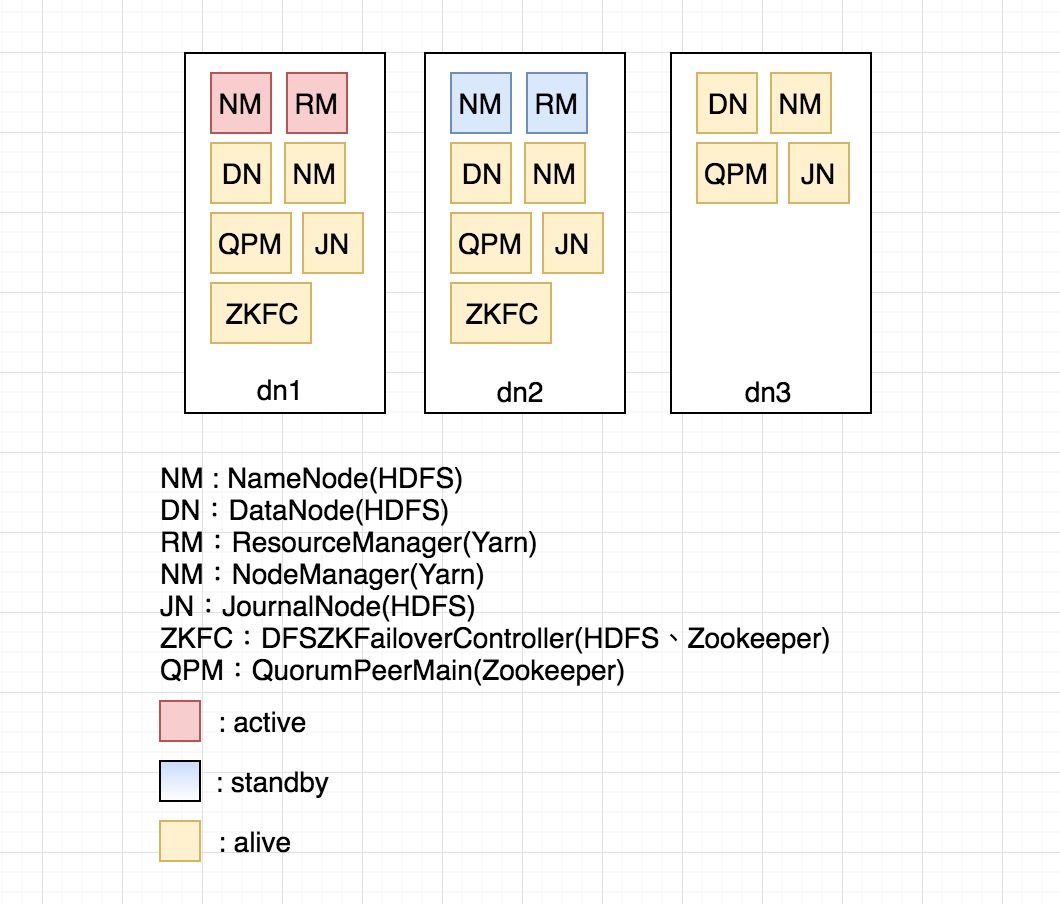
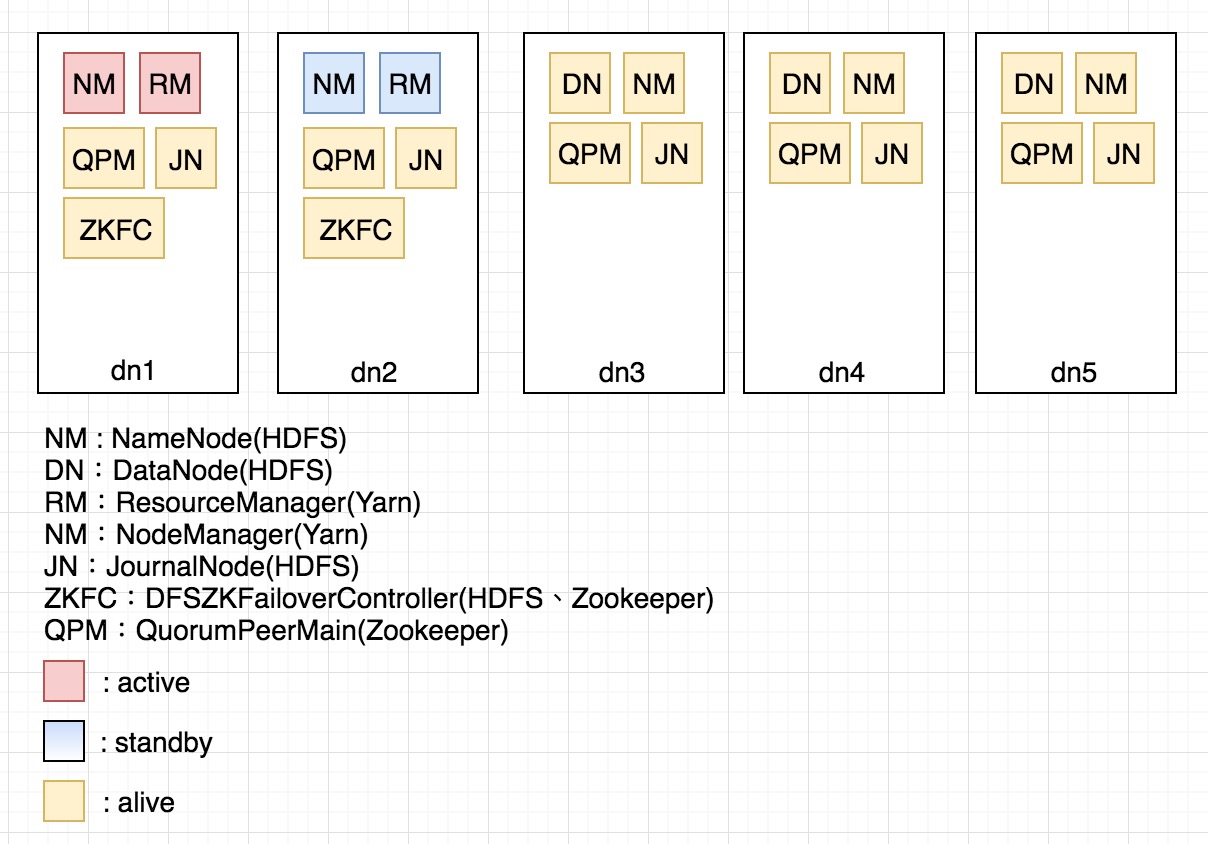
- 5 台架構
整合步驟 :
1.install & config Zookeeper
2.Hadoop with Zookeeper
3.HDFS Nodemanager HA by Zookeeper
4.Yarn Resourcemanager HA by Zookeeper
5.Initializing HA state in ZooKeeper
6.Start HA cluster
原來的 active 掛後,修復步驟參考 :
1.restart fail active machine
目前遇到的問題參考 :
1.問題排除
install & config Zookeeper
下載 zookeeper download page 解壓縮後,到 conf 底下,將zoo_sample.cfg 複製成 zoo.cfg
- 修改 zoo.cfg
修改 data 存放的目錄dataDir=/opt/zookeeper-3.4.13/data加上 zookeeper 的 cluster
server.1=dmpn1:2888:3888 server.2=dmpn2:2888:3888 server.3=dmpn3:2888:3888範例參考 :
tickTime=2000 initLimit=10 syncLimit=5 dataDir=/opt/zookeeper-3.4.13/data clientPort=2181 server.1=dmpn1:2888:3888 server.2=dmpn2:2888:3888 server.3=dmpn3:2888:3888 - 建立 myid 檔案
在 zoo.cfg 設定的 dataDir 底下建立 myid 檔案
dataDir=/opt/zookeeper-3.4.13/datamyid 檔案內容就根據 zoo.cfg 的設定
server.1=dmpn1:2888:3888 server.2=dmpn2:2888:3888 server.3=dmpn3:2888:3888第一台就寫 1 , 第二台寫 2 , 第三台寫 3
Hadoop with Zookeeper
修改 core-site.xml(/opt/hadoop-2.9.0/etc/hadoop)
<property>
<name>fs.defaultFS</name>
<value>hdfs://dmpcluster</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/zookeeper-3.4.13/journaldata</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>dmpn1:2181,dmpn2:2181,dmpn3:2181</value>
</property>
Note :
- JournalNodes 至少要啟動 3 台,奇數台(3,5,7,..),N 台 JournalNodes 則系統能容忍至少 (N-1)/2 台機器掛掉.JournalNodes 的功用有點像是沒有 HA 時的 secondary namenode.
- 在 HA 的 cluster 的環境中 standby Namenode 已經做了 namespace 狀態的 checkpoints 機制,所以不需要啟動 Secondary NameNode, CheckpointNode 或 BackupNode.
- NameNode 能夠自動切換的核心是透過 ZKFC (ZKFC:DFSZKFailoverController),ZKFC 會定期的傳送 Namenode 的狀況給 Zookeeper. KFC 的 HealthMonitor 是監控 Namenode,ActiveStandbyElector 是監控 Zookeeper 的 node.
- 當一個 Namenode 成功切換為 Active 時,Zookeeper 會建立一個 znode 來保留當前 Active Namenode 的一些資訊.當 Active Namenode 掛掉時,會把 znode 刪除並觸發下一次 Active Namenode. 所以 ZK 可以保證最多只能有一個節點能夠成功建立 znode 成為當前的 Active Namenode.
HDFS Nodemanager HA by Zookeeper
修改 hdfs-site.xml (/opt/hadoop-2.9.0/etc/hadoop)
<property>
<name>dfs.nameservices</name>
<value>dmpcluster</value>
</property>
<property>
<name>dfs.ha.namenodes.dmpcluster</name>
<value>nn1,nn2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.dmpcluster.nn1</name>
<value>dmpn1:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.dmpcluster.nn2</name>
<value>dmpn2:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.dmpcluster.nn1</name>
<value>dmpn1:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.dmpcluster.nn2</name>
<value>dmpn2:50070</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://dmpn1:8485;dmpn2:8485;dmpn3:8485/dmpcluster</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.dmpcluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/miuser/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
原本 fencing 這樣設定,如果只用 kill -9 {namenodePID} 可以 HA,但機器關掉後沒辦法 HA
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
所以改成
<property>
<name>dfs.ha.fencing.methods</name>
<value>shell(/bin/true)</value>
</property>
dfs.namenode.shared.edits.dir 這個參數是在設定 2 台 namenode 的 metadata 要能夠同步. active 會不斷寫入,而 standby 會一直讀取更新 metadata.而這邊的設定是使用 Quorum Journal Manager 來管理.
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://dmpn1:8485;dmpn2:8485;dmpn3:8485/dmpcluster</value>
</property>
另外一種方式是用 NFS(Network FileSystem) 的方式同步 metadata.讓 namenode 可以讀取到同一個目錄.
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>file:///mnt/filer1/dfs/ha-name-dir-shared</value>
</property>
dfs.ha.automatic-failover.enabled 設為 true 時,start-dfs.sh 或 start-all.sh 時會自動帶起 zkfc daemon(DFSZKFailoverController).
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
如果沒有自動帶起的話可以手動起,只要起在 2 台 Namenode 的機器上即可
hadoop-daemon.sh start zkfc
Yarn Resourcemanager HA by Zookeeper
修改 yarn-site.xml
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>dmpcluster</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>dmpn1</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>dmpn2</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>dmpn1:8088</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>dmpn2:8088</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm1</name>
<value>dmpn1:8030</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm2</name>
<value>dmpn2:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm1</name>
<value>dmpn1:8031</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm2</name>
<value>dmpn2:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address.rm1</name>
<value>dmpn1:8033</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address.rm2</name>
<value>dmpn2:8033</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>dmpn1:2181,dmpn2:2181,dmpn3:2181</value>
</property>
Initializing HA state in ZooKeeper
記得要先啟動 zookeeper 才可以把 znode 加入.
hdfs zkfc -formatZK
這邊如果遇到啟動不了的話,通常都是防火牆跟 /etc/hosts 的問題,所以要先確認這兩個地方 :
Unable to start failover controller. Unable to connect to ZooKeeper quorum at node1:2181,node2:2181,node3:2181.
Start HA cluster
1.在每台機器(dn1,dn2,dn3)啟動 zookeeper
zkServer.sh start
2.啟動每台機器(dn1,dn2,dn3)的journalnode,不然執行 hdfs namenode -format 時會出現 8485 port 連不到
hadoop-daemon.sh start journalnode
3.到 dn1 那台 format namenode
hdfs namenode -format
4.在 dn1 啟動 cluster
start-all.sh
5.在 dn2 的 namenode 下 bootstrapStandby
hdfs namenode -bootstrapStandby
6.再啟動 dn2 standby 的 namenode
hadoop-daemon.sh start namenode
7.啟動 dn2 的 Yarn Resourcemanager
yarn-daemon.sh start resourcemanager
restart fail active machine
將原來掛掉的 active namenode (dn1) 重新啟動修復步驟 :
1.啟動 zookeeper
./zkServer.sh start
2.啟動 DFSZKFailoverController
hadoop-daemon.sh start zkfc
3.啟動 journalnode
hadoop-daemon.sh start journalnode
4.啟動 namenode
hadoop-daemon.sh start namenode
5.啟動 datanode
hadoop-daemon.sh start datanode
6.啟動 resourcemanager
yarn-daemon.sh start resourcemanager
7.啟動 nodemanager
yarn-daemon.sh start nodemanager
8.確認 namenode active / standby 狀態
hdfs haadmin -getServiceState nn1
hdfs haadmin -getServiceState nn2
9.確認 resourcemanager active / standby 狀態
yarn rmadmin -getServiceState rm1
yarn rmadmin -getServiceState rm2
10.確認 cat hdfs 檔案是否正常
hdfs dfs -cat /temp/wordcount/workcount.txt
11.測試 spark-submit 的 yarn cluster mode 是否正常
spark-submit --class com.example.job.WordCount --master yarn --deploy-mode cluster wordcount.jar /temp/wordcount/workcount.txt /temp/data
問題排除
[問題] HA 2 台 namenode 的資料(hdfs資料)不一致的問題,或著遇到 active 掛掉 standby 啟動時 hdfs cat 檔案時出現下列錯誤訊息
2018-10-02 15:14:02 WARN DFSClient:981 - Could not obtain block: BP-106148578-192.168.3.13-1538386246613:blk_1073741825_1001 file=/temp/wordcount/workcount.txt No live nodes contain current block Block locations: Dead nodes: . Throwing a BlockMissingException
2018-10-02 15:14:02 WARN DFSClient:907 - DFS Read
org.apache.hadoop.hdfs.BlockMissingException: Could not obtain block: BP-106148578-192.168.3.13-1538386246613:blk_1073741825_1001 file=/temp/wordcount/workcount.txt
at org.apache.hadoop.hdfs.DFSInputStream.chooseDataNode(DFSInputStream.java:984)
at org.apache.hadoop.hdfs.DFSInputStream.blockSeekTo(DFSInputStream.java:642)
at org.apache.hadoop.hdfs.DFSInputStream.readWithStrategy(DFSInputStream.java:882)
at org.apache.hadoop.hdfs.DFSInputStream.read(DFSInputStream.java:934)
at java.io.DataInputStream.read(DataInputStream.java:149)
at org.apache.hadoop.mapreduce.lib.input.UncompressedSplitLineReader.fillBuffer(UncompressedSplitLineReader.java:62)
at org.apache.hadoop.util.LineReader.readDefaultLine(LineReader.java:216
確認 2 台 namenode 的 metadata 的同步設定.
如果是用 JournalNode 要用 jps 檢查是否有啟動.
如果是用 NFS 要確認 2 台 nmaenode 是否有讀取到 mount 的同一目錄.
- 檢查 hdfs-site.xml
[問題] HA 切換時 datanode 好像會掛掉,或著出現類似下面錯誤訊息
2018-09-27 19:18:29,634 WARN org.apache.hadoop.hdfs.server.common.Storage: Failed to add storage directory [DISK]file:/data/hadoop/dfs/data/
java.io.IOException: Incompatible clusterIDs in /data/hadoop/dfs/data: namenode clusterID = CID-92ddbfd6-6a07-454b-8848-22f9f15d2621; datanode clusterID = CID-4f03e59a-ea80-42a5-8a7d-a6db94c0cc19
at org.apache.hadoop.hdfs.server.datanode.DataStorage.doTransition(DataStorage.java:760)
at org.apache.hadoop.hdfs.server.datanode.DataStorage.loadStorageDirectory(DataStorage.java:293)
或著
2018-09-27 19:18:17,387 WARN org.apache.hadoop.hdfs.server.namenode.FSNamesystem: Encountered exception loading fsimage
java.io.FileNotFoundException: /data/hadoop/dfs/name/current/VERSION (Permission denied)
at java.io.RandomAccessFile.open0(Native Method)
at java.io.RandomAccessFile.open(RandomAccessFile.java:316)
at java.io.RandomAccessFile.<init>(RandomAccessFile.java:243)
at org.apache.hadoop.hdfs.server.common.StorageInfo.readPropertiesFile(StorageInfo.java:244)
at org.apache.hadoop.hdfs.server.namenode.NNStorage.readProperties(NNStorage.java:650)
at org.apache.hadoop.hdfs.server.namenode.FSImage.recoverStorageDirs(FSImage.java:381)
at org.apache.hadoop.hdfs.server.namenode.FSImage.recoverTransitionRead(FSImage.java:220)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.loadFSImage(FSNamesystem.java:1048)
HA 機制沒同步好,standby 的 namenode 可能沒有下 bootstrapStandby 下成 namenode -format.導致 namnode 與 datanode 的 version 沒有對到.
1.先把服務都關掉,然後清空每台的暫存資料 :
sudo rm -fr /data/hadoop/dfs/name/current
sudo rm -fr /data/hadoop/dfs/data/current
rm -fr /tmp/hadoop*
2.啟動 journalnode
hadoop-daemon.sh start journalnode
3.format active 的 namenode :
hdfs namenode -format
4.在 active 的機器上把服務起起來
start-all.sh
5.在 standby 下 bootstrapStandby
hdfs namenode -bootstrapStandby
6.再啟動 standby 的 namenode
./hadoop-daemon.sh start namenode
修改 hadoop temp 目錄的路徑
在 core-site.xml 加上要設定的路徑(預設是/tmp/hadoop/hadoop-${user.name}) :
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop-2.9.0/tmp/hadoop/hadoop-${user.name}</value>
<description>A base for other temporary directories.</description>
</property>
[問題] 出現下列錯誤訊息
2018-11-27 12:10:38,505 WARN org.apache.hadoop.hdfs.server.common.Storage: Failed to add storage directory [DISK]file:/data/hadoop/dfs/data/
java.io.FileNotFoundException: /data/hadoop/dfs/data/in_use.lock (Permission denied)
at java.io.RandomAccessFile.open0(Native Method)
at java.io.RandomAccessFile.open(RandomAccessFile.java:316)
at java.io.RandomAccessFile.<init>(RandomAccessFile.java:243)
at org.apache.hadoop.hdfs.server.common.Storage$StorageDirectory.tryLock(Storage.java:782)
at org.apache.hadoop.hdfs.server.common.Storage$StorageDirectory.lock(Storage.java:754)
at org.apache.hadoop.hdfs.server.common.Storage$StorageDirectory.analyzeStorage(Storage.java:567)
at org.apache.hadoop.hdfs.server.datanode.DataStorage.loadStorageDirectory(DataStorage.java:270)
at org.apache.hadoop.hdfs.server.datanode.DataStorage.loadDataStorage(DataStorage.java:409)
at org.apache.hadoop.hdfs.server.datanode.DataStorage.addStorageLocations(DataStorage.java:388)
at org.apache.hadoop.hdfs.server.datanode.DataStorage.recoverTransitionRead(DataStorage.java:556)
[解決] :
刪掉 in_use.lock
sudo rm -fr /data/hadoop/dfs/data/in_use.lock
[問題] datanode 起不來
java.net.BindException: Problem binding to [0.0.0.0:50010] java.net.BindException: Address already in use; For more details see: http://wiki.apache.org/hadoop/BindException
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:423)
at org.apache.hadoop.net.NetUtils.wrapWithMessage(NetUtils.java:824)
at org.apache.hadoop.net.NetUtils.wrapException(NetUtils.java:735)
at org.apache.hadoop.ipc.Server.bind(Server.java:561)
at org.apache.hadoop.ipc.Server.bind(Server.java:533)
at org.apache.hadoop.hdfs.net.TcpPeerServer.<init>(TcpPeerServer.java:52)
at org.apache.hadoop.hdfs.server.datanode.DataNode.initDataXceiver(DataNode.java:1116)
at org.apache.hadoop.hdfs.server.datanode.DataNode.startDataNode(DataNode.java:1369)
[解決] : 原本的 user(miuser) 底下都找不到被 bind 的 50010
netstat -anp | grep 50010
netstat -ano | grep 50010
ps -aux | grep 50010
pgrep -f datanode
pgrep -f journalnode
後來切換到另一個 user(yarn),有找到一個 process 佔用該 port
yarn@dmpn5:~>netstat -ano | grep 50010
tcp 0 0 0.0.0.0:50010 0.0.0.0:* LISTEN off (0.00/0/0)
找有關 datanode 的 PID
yarn@dmpn5:~>pgrep -f datanode
159789
把佔用的 port 刪掉
yarn@dmpn5:~>ps -aux | grep 159789
yarn 61224 0.0 0.0 112616 732 pts/1 S+ 12:45 0:00 grep --color=auto 159789
root 159789 0.1 0.3 3039556 878360 ? Sl May15 464:44 /usr/lib/jvm/jdk1.8.0_151//bin/java -Dproc_datanode -Xmx1000m -Djava.net.preferIPv4Stack=true -Dhadoop.log.dir=/opt/hadoop-2.9.0/logs -Dhadoop.log.file=hadoop.log -Dhadoop.home.dir=/opt/hadoop-2.9.0 -Dhadoop.id.str=root -Dhadoop.root.logger=INFO,console -Dhadoop.policy.file=hadoop-policy.xml -Djava.net.preferIPv4Stack=true -Djava.net.preferIPv4Stack=true -Djava.net.preferIPv4Stack=true -Dhadoop.log.dir=/opt/hadoop-2.9.0/logs -Dhadoop.log.file=hadoop-root-datanode-dmpn5.log -Dhadoop.home.dir=/opt/hadoop-2.9.0 -Dhadoop.id.str=root -Dhadoop.root.logger=INFO,RFA -Dhadoop.policy.file=hadoop-policy.xml -Djava.net.preferIPv4Stack=true -server -Dhadoop.security.logger=ERROR,RFAS -Dhadoop.security.logger=ERROR,RFAS -Dhadoop.security.logger=ERROR,RFAS -Dhadoop.security.logger=INFO,RFAS org.apache.hadoop.hdfs.server.datanode.DataNode
sudo kill -9 159789
如果有用到 external shuffle service 的話要記得 :
Put spark-2.1.1-yarn-shuffle.jar into lib folder of yarn.
cp <SPARK_HOME>/yarn/spark-<version>-yarn-shuffle.jar /opt/hadoop-2.7.3/share/hadoop/yarn/lib/
[問題] namenode 掛掉
2019-04-09 19:12:29,121 WARN org.apache.hadoop.hdfs.qjournal.client.QuorumJournalManager: Waited 17015 ms (timeout=20000 ms) for a response for sendEdits. Succeeded so far: [192.168.6.31:8485]
2019-04-09 19:12:30,122 WARN org.apache.hadoop.hdfs.qjournal.client.QuorumJournalManager: Waited 18016 ms (timeout=20000 ms) for a response for sendEdits. Succeeded so far: [192.168.6.31:8485]
2019-04-09 19:12:31,123 WARN org.apache.hadoop.hdfs.qjournal.client.QuorumJournalManager: Waited 19017 ms (timeout=20000 ms) for a response for sendEdits. Succeeded so far: [192.168.6.31:8485]
2019-04-09 19:12:32,107 FATAL org.apache.hadoop.hdfs.server.namenode.FSEditLog: Error: flush failed for required journal (JournalAndStream(mgr=QJM to [192.168.6.31:8485, 192.168.6.32:8485, 192.168.6.33:8485], stream=QuorumOutputStream starting at txid 104137))
java.io.IOException: Timed out waiting 20000ms for a quorum of nodes to respond.
at org.apache.hadoop.hdfs.qjournal.client.AsyncLoggerSet.waitForWriteQuorum(AsyncLoggerSet.java:137)
at org.apache.hadoop.hdfs.qjournal.client.QuorumOutputStream.flushAndSync(QuorumOutputStream.java:107)
at org.apache.hadoop.hdfs.server.namenode.EditLogOutputStream.flush(EditLogOutputStream.java:113)
at org.apache.hadoop.hdfs.server.namenode.EditLogOutputStream.flush(EditLogOutputStream.java:107)
at org.apache.hadoop.hdfs.server.namenode.JournalSet$JournalSetOutputStream$8.apply(JournalSet.java:533)
at org.apache.hadoop.hdfs.server.namenode.JournalSet.mapJournalsAndReportErrors(JournalSet.java:393)
at org.apache.hadoop.hdfs.server.namenode.JournalSet.access$100(JournalSet.java:57)
at org.apache.hadoop.hdfs.server.namenode.JournalSet$JournalSetOutputStream.flush(JournalSet.java:529)
at org.apache.hadoop.hdfs.server.namenode.FSEditLog.logSync(FSEditLog.java:707)
at org.apache.hadoop.hdfs.server.namenode.FSEditLogAsync.run(FSEditLogAsync.java:188)
at java.lang.Thread.run(Thread.java:748)
2019-04-09 19:12:32,108 WARN org.apache.hadoop.hdfs.qjournal.client.QuorumJournalManager: Aborting QuorumOutputStream starting at txid 104137
有可能對 HDFS 大量操作時,或網路問題狀況出現
[解決] : 修改 hdfs-site.xml
<property>
<name>dfs.qjournal.write-txns.timeout.ms</name>
<value>60000</value>
</property>
<property>
<name>dfs.qjournal.start-segment.timeout.ms</name>
<value>60000</value>
</property>
<property>
<name>dfs.qjournal.select-input-streams.timeout.ms</name>
<value>60000</value>
</property>
修改core-site.xml
<property>
<name>ipc.client.connect.timeout</name>
<value>60000</value>
</property>
指令速查
- 查看所有 node 的狀態
hdfs dfsadmin -report - 查看 zookeeper 的 leader 或 follower
zkServer.sh status - 查看正在 listen 的 port
lsof -i -P -n | grep LISTEN sudo netstat -plten | grep LISTEN -> 要 root - 啟動、關閉、查看防火牆狀態(centos 7)
systemctl status firewalld systemctl start firewalld systemctl stop firewalld - 查看目前防火墻設定的 port
sudo firewall-cmd --zone=public --list-ports - 加上防火牆的 port,並 reload
sudo firewall-cmd --zone=public --permanent --add-port=8088/tcp firewall-cmd --reload - gen rsa key 及複製到各機器(ssh 免密碼登入)
su - muser ssh-keygen -t rsa ssh-copy-id -i ~/.ssh/id_rsa.pub muser@dn1 ssh-copy-id -i ~/.ssh/id_rsa.pub muser@dn2 ssh-copy-id -i ~/.ssh/id_rsa.pub muser@dn3 - hdfs HA 相關指令
hdfs haadmin -failover nn1 nn2 hdfs haadmin -transitionToActive --forcemanual nn1 hdfs haadmin -getServiceState nn1 hdfs haadmin -transitionToActive --forcemanual --forceactive nn1 hdfs haadmin -transitionToStandby --forcemanual nn2 - yarn HA 相關指令
yarn rmadmin -getServiceState rm1 yarn rmadmin -getServiceState rm2 - yarn service 相關指令
yarn-daemon.sh start resourcemanager yarn-daemons.sh start nodemanager yarn resourcemanager -format-state-store - HDFS service 相關指令
hadoop-daemon.sh start namenode hadoop-daemon.sh start datanode hadoop-daemon.sh start journalnode hadoop-daemon.sh start zkfc
實際設定值參考
- core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://dmpcluster</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/zookeeper-3.4.13/journaldata</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>dmpn1:2181,dmpn2:2181,dmpn3:2181</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
</configuration>
- hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>dfs.name.dir</name>
<value>file:///data/hadoop/dfs/name</value>
<final>true</final>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///data/hadoop/dfs/data</value>
<final>true</final>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.blocksize</name>
<value>134217728</value>
</property>
<property>
<name>dfs.namenode.checkpoint.dir</name>
<value>file:///data/def/namesecondary</value>
</property>
<property>
<name>dfs.nameservices</name>
<value>dmpcluster</value>
</property>
<property>
<name>dfs.ha.namenodes.dmpcluster</name>
<value>nn1,nn2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.dmpcluster.nn1</name>
<value>dmpn1:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.dmpcluster.nn2</name>
<value>dmpn2:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.dmpcluster.nn1</name>
<value>dmpn1:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.dmpcluster.nn2</name>
<value>dmpn2:50070</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://dmpn1:8485;dmpn2:8485;dmpn3:8485/dmpcluster</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.dmpcluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>shell(/bin/true)</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/miuser/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
</configuration>
- yarn-site.xml
<?xml version="1.0"?>
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>dmpn1</value>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>3</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>24576</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-vcores</name>
<value>18</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>8192</value>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>6</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.nodemanager.log-aggregation.roll-monitoring-interval-seconds</name>
<value>3600</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>1209600</value>
</property>
<property>
<name>yarn.log-aggregation.retain-check-interval-seconds</name>
<value>172800</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>spark_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.spark_shuffle.class</name>
<value>org.apache.spark.network.yarn.YarnShuffleService</value>
</property>
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>dmpcluster</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>dmpn1</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>dmpn2</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>dmpn1:8088</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>dmpn2:8088</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm1</name>
<value>dmpn1:8030</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm2</name>
<value>dmpn2:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm1</name>
<value>dmpn1:8031</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm2</name>
<value>dmpn2:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address.rm1</name>
<value>dmpn1:8033</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address.rm2</name>
<value>dmpn2:8033</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>dmpn1:2181,dmpn2:2181,dmpn3:2181</value>
</property>
</configuration>
- zoo.cfg
tickTime=2000
initLimit=100
syncLimit=5
dataDir=/opt/zookeeper-3.4.13/data
clientPort=2181
server.1=dmpn1:2888:3888
server.2=dmpn2:2888:3888
server.3=dmpn3:2888:3888
- Java Namenode HA 寫法 :
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
FileSystem hdfs;
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://nameservice1");
conf.set("dfs.nameservices", "nameservice1");
conf.set("dfs.ha.namenodes.nameservice1", "namenode76,namenode81");
conf.set("dfs.namenode.rpc-address.nameservice1.namenode76", "darhhdlm1:8020");
conf.set("dfs.namenode.rpc-address.nameservice1.namenode81", "darhhdlm2:8020");
conf.set("dfs.client.failover.proxy.provider.nameservice1", "org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider");
conf.set("fs.hdfs.impl", "org.apache.hadoop.hdfs.DistributedFileSystem");
hdfs = FileSystem.get(conf);
參考資料
HDFS namenode HA using QJM
HDFS namenode HA using NFS
Yarn ResourceManager HA ZKFC 原理 Hadoop HA 筆記
NameNode HA
Zookeeper getting start