hadoop day 2 (spark on yarn performance)
針對 spark job 在 yarn 上面執行的效能調整,在 GCP 上面使用三台機器做一個 hadoop cluster 做測試.
測試檔案的資料格式大概長這樣,然後大小為 1G , 10200000 筆資料 :
jackalhelix68714,picbear.com/ebcbuzz/cannotmappin,2018-10-22 06:08:11,2018-10-22 06:08:57,33,530214
butterflyforest75334240,www.theguardian.com/media/iplayer,2018-10-13 12:07:15,2018-10-13 12:08:34,70,2487
lightningsmall9571044,picbear.com/ebcbuzz/cannotmappin,2018-10-17 06:07:15,2018-10-17 06:08:10,467706,58
主要就是跑 spark job 處理上面的檔案資料後,寫入 Redis.
一台機器的規格
4 Core , 15G
Hadoop Cluster 規格,每一台保留 2 Core 及 5G 的 Memory 給系統使用 :
Memory Total 30 GB
VCores Total 6
執行 “update.sh” 測試 :
(1)spark-submit 參數 :
yarn cluster mode , driver-memory 5g , executor-memory 5g , executor-cores 2 , num-executors 3
(2)yarn 執行狀態 :
Containers Running : 3 個, Memory Used : 18GB , VCores Used : 3
(3)執行時間 :
17:18:52 ~ 18:21:44 , 63 分鐘
(4)redis 資料 :
約 20399995 筆
使用上面的 spark-submit 參數,一開始只有 3 個 container 在跑,資源也沒有用滿.跑了 1 小時左右. 所以調整了一下參數,算法如下 :
1台機器 2 Core / 每個 executor 1 個 Core 所以每一台機器最多只能跑 2 個 executor. 1台機器 2 個 executor * 3 台,所以最多有 6 個 executor 可以執行,但扣掉 1 個 Driver 所以剩 5 個 executor. 1台機器的 Memory 有 10G / 2 個 executor,1 個 executor 可以使用的 Memory 公式算法大概是 :
1 個 executor 可以使用的 Memory - Min(384 , 0.1 * (1 個 executor 可以使用的 Memory)) - (Driver 使用的 Memory + Min(384 , (0.1 * (Driver 使用的 Memory))))
或著是將 0.1 改成 0.7
1 個 executor 可以使用的 Memory - Min(384 , 0.7 * (1 個 executor 可以使用的 Memory)) - (Driver 使用的 Memory + Min(384 , (0.7 * (Driver 使用的 Memory))))
所以大概是
5G - Min(384 , 0.1 * 5G) = 5G - 0.5G = 4.5G
10G - 4.5G 剩 5.5 給 driver,上面的例子 driver-memory 給 5g,實際會用到 5 + 0.5 = 5.5,所以可能不夠用.
如果是用 0.7 算的話
5G - Min(384 , 0.7 * 5G) = 5G - 3.5G = 1.5G 完全不夠給 Driver.
所以修改 spark-submit 參數如下 :
(1)spark-submit 參數 :
yarn cluster mode , driver-memory 7g , executor-memory 7g , executor-cores 1 , num-executors 5
(2)yarn 執行狀態 :
Containers Running : 6 個 , Memory Used : 48 GB , VCores Used : 6 core
(3)執行時間 :
10:17:34 ~ 10:57:48 , 40 分鐘
(4)redis 資料 :
所以 Memory 的計算,0.1 的算法
5 個 executors * (7G + 7G * 0.1) = 5 * 7.7 = 38.5
1 個 driver * (7G + 7G * 0.1) = 7.7
38.5 + 7.7 = 46.2
0.7 的算法
5 個 executors * (7G + 7G * 0.7) = 5 * 11.9 = 59.5
1 個 driver * (7G + 7G * 0.7) = 11.9
59.5 + 11.9 = 71.4
Memory 實際使用了 48G,所以感覺用 0.7 去估比較保險.
提升機器規格做測試,一台機器的規格
8 Core , 30G
Hadoop Cluster 規格,每一台保留 2 Core 及 8G 的 Memory 給系統使用 :
Memory Total 66 GB
VCores Total 18
執行 “update.sh” 測試 :
(1)spark-submit 參數 :
yarn cluster mode , driver-memory 7g , executor-memory 7g , executor-cores 2 , num-executors 8
(2)yarn 執行狀態 :
Containers Running : 6 個 , Memory Used : 48 GB , VCores Used : 6 core
(3)執行時間 :
17:37:57 ~ 18:12:07 , 35 分鐘
(4)redis 資料 :
info keyspace
n1 -> db0:keys=6799307
n2 -> db0:keys=6801872
n3 -> db0:keys=6798816
每 1 個 executor 應該要是 2 個 core 但在 Yarn 上面看到的還是只有 6 個 core.
修改 capacity-scheduler.xml 的 yarn.scheduler.capacity.resource-calculator 參數,原本是
<property>
<name>yarn.scheduler.capacity.resource-calculator</name>
<value>org.apache.hadoop.yarn.util.resource.DefaultResourceCalculator</value>
<description>
The ResourceCalculator implementation to be used to compare
Resources in the scheduler.
The default i.e. DefaultResourceCalculator only uses Memory while
DominantResourceCalculator uses dominant-resource to compare
multi-dimensional resources such as Memory, CPU etc.
</description>
</property>
改成使用 DominantResourceCalculator :
<property>
<name>yarn.scheduler.capacity.resource-calculator</name>
<value>org.apache.hadoop.yarn.util.resource.DominantResourceCalculator</value>
<description>
The ResourceCalculator implementation to be used to compare
Resources in the scheduler.
The default i.e. DefaultResourceCalculator only uses Memory while
DominantResourceCalculator uses dominant-resource to compare
multi-dimensional resources such as Memory, CPU etc.
</description>
</property>
修改 capacity-scheduler.xml 只需要下
yarn rmadmin -refreshQueues
參考 yarn 資訊不準確 修改後再測試
(1)spark-submit 參數 :
yarn cluster mode , driver-memory 7g , executor-memory 7g , executor-cores 2 , num-executors 6
(2)yarn 執行狀態 :
Containers Running : 6 個 , Memory Used : 48 GB , VCores Used : 12 core
spark 執行狀態 :
Task : 8 個 ,
executor-cores : 2 Cores
(3)執行時間 :
14:54:19 ~ 15:26:05 , 32 分鐘
(4)redis 資料 : 20399989 筆左右
可以看到 core 是正確的了,但執行時間並沒有提升太多.
再次提升機器規格做測試,一台機器的規格
16 Core , 60G
Hadoop Cluster 規格,每一台保留 4 Core 及 12G 的 Memory 給系統使用 :
Memory Total 144 GB
VCores Total 36
這次提升了很多 core 跟 memory 所以重新定義 yarn 的參數 yarn-site.xml :
yarn.scheduler.maximum-allocation-mb : 49152/3 = 16384 = 16G
yarn.scheduler.minimum-allocation-mb : 49152/9 = 5461 = 5.3 G
yarn.scheduler.maximum-allocation-vcores : 36/3 = 12
yarn.scheduler.minimum-allocation-vcores : 36/9 = 4 Core
yarn.nodemanager.resource.memory-mb : 1024 * 48 = 49152
yarn.nodemanager.resource.cpu-vcores : 36 Core
執行 “update.sh” 測試 :
(1)spark-submit 參數 :
yarn cluster mode , driver-memory 8g , executor-memory 5g , executor-cores 4 , num-executors 24
(2)yarn 執行狀態 :
Containers Running : 12 個 , Memory Used : 127.99 GB , VCores Used : 48 core
spark 執行狀態 :
executors : 11 個 executor + 1 個 driver
Task : 8 個
executor-cores : 4 Cores
(3)執行時間 :
17:42:14 ~ 18:14 , 32 分鐘
(4)redis 資料 : 20400541 筆左右
執行 “update.sh” 測試 :
(1)spark-submit 參數 :
yarn cluster mode , driver-memory 12g , executor-memory 5g , executor-cores 2 , num-executors 24
(2)yarn 執行狀態 :
Containers Running : 12 個 , Memory Used : 133.33 GB , VCores Used : 48 core
spark 執行狀態 :
executors : 11 個 executor + 1 個 driver
Task : 8 個
executor-cores : 2 Cores
(3)執行時間 :
18:19:23 ~ 18:49 , 30 分鐘
(4)redis 資料 : 20400541 筆左右
不管怎麼調速度都差不多,而且 spark 的 task 最多都只切到 8 個 :
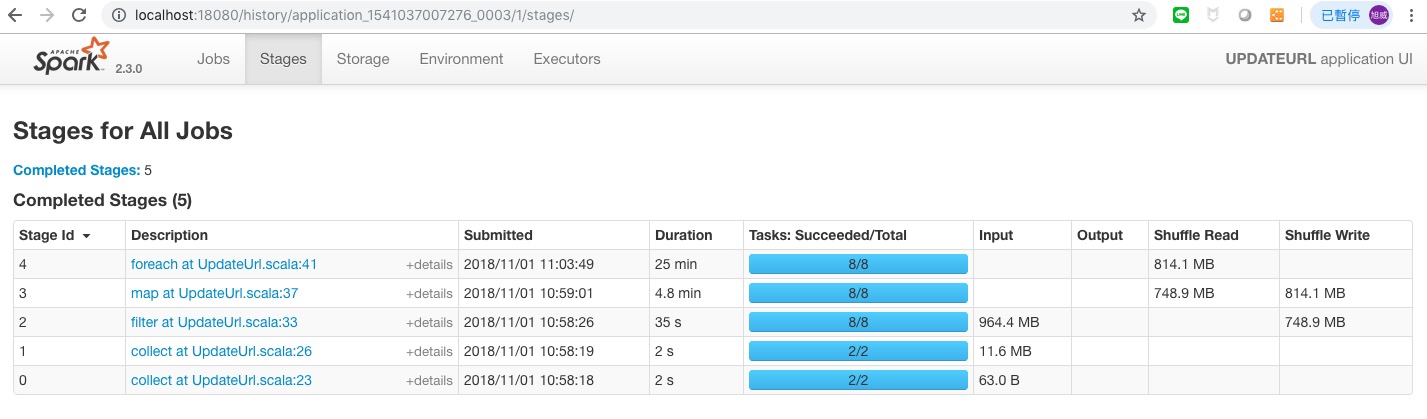
於是想到會不會跟 HDFS 的 Block 數有關,因為程式有寫到 sc.textFile 而主程式架構大致上為 :
sc.textFile(inDir).map { str =>
...
}.filter(
...
).reduceByKey(
...
).map { case (id, person) =>
...
}.reduceByKey(
...
).foreach { case (id, person) =>
...
}
查看目前的 blocksize
> hdfs getconf -confKey dfs.blocksize
134217728
修改 hdfs block size 將 128MB 改成 64M,修改 hdfs-site.xml :
<property>
<name>dfs.blocksize</name>
<value>134217728</value>
</property>
改成
<property>
<name>dfs.blocksize</name>
<value>67108864</value>
</property>
改完之後重啟 Hadoop cluster,記得 HDFS 的檔案要重新放,不然舊 HDFS 檔案的 blocksize 還會是舊的.
執行 “update.sh” 測試 :
(1)spark-submit 參數 :
yarn cluster mode , driver-memory 9g , driver-cores 12 , executor-memory 14g(15g會超過) , executor-cores 10 , num-executors 5
(2)yarn 執行狀態 :
Containers Running : 6 個 , Memory Used : 90.66 GB , VCores Used : 72 core
spark 執行狀態 :
executors : 5 個 executor + 1 個 driver
Task : 15 個
executor-cores : 10 Cores
driver : 5G
(3)執行時間 :
12:36:38 ~ 12:55:41 , 20 分鐘
這時候 Task 就變 15 個了,而且時間又快了 10 分鐘,公式如下
HDFS File Size / HDFS Block Size
所以原本的 8 個 task 是
1024M / 128M = 8
修改後變
1024M / 64M = 16 (實際只有15)
所以看起來增加 task 數,可以加快執行速度。
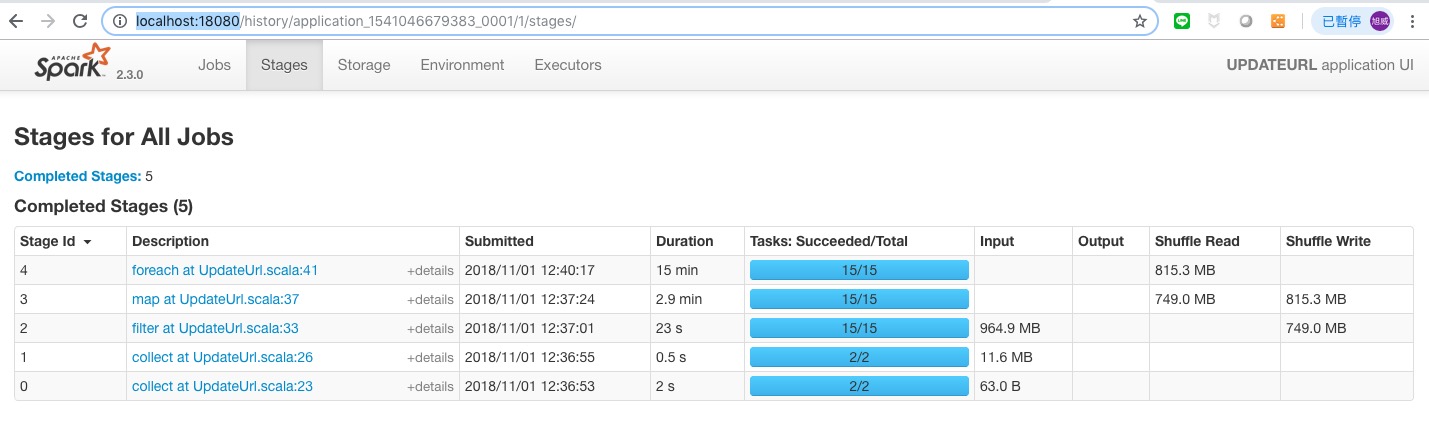
但由於要讀取 HDFS 檔案的關係 task 數受限於 HDFS 的 Block size.那想再增加 task 數該怎麼辦. 這時候可以利用 repartition 或 coalesce 這兩個 API 改變 partition 的數量. 目前理解是要增加 partition 數使用 repartition,要減少 partition 數要使用 coalesce. 減少 partition 時使用 coalesce 的話好像不會進行 shuffle,其他的動作都會產生 shuffle 增加額外的負擔.
先切 100 個 partition 測試,程式改成這樣 :
sc.textFile(inDir).map { str =>
...
}.filter(
...
).reduceByKey(
...
).repartition(100)
.map { case (id, person) =>
...
}.reduceByKey(
...
).foreach { case (id, person) =>
...
}
執行 “update.sh” 測試 :
(1)spark-submit 參數 :
yarn cluster mode , driver-memory 9g , driver-cores 12 , executor-memory 14g(15g會超過) , executor-cores 10 , num-executors 5
(2)yarn 執行狀態 :
Containers Running : 6 個 , Memory Used : 90.66 GB , VCores Used : 72 core
spark 執行狀態 :
executors : 5 個 executor + 1 個 driver
Task : 15 個
executor-cores : 10 Cores
driver : 5G
(3)執行時間 :
16:37:50 ~ 16:46:46 , 9 分鐘
速度又提升不少只花了 9 分鐘.
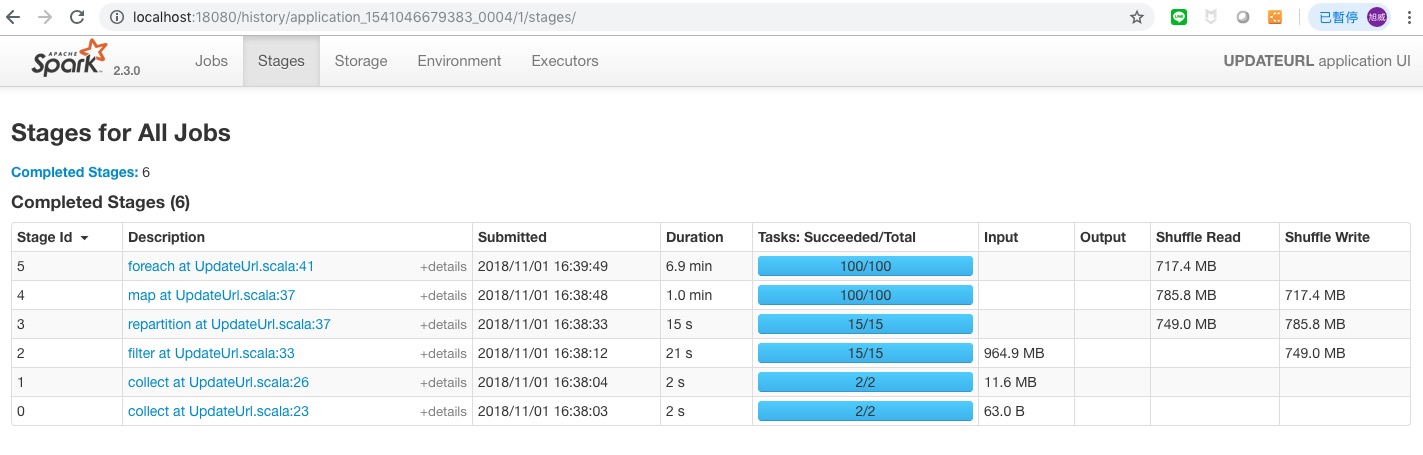
那調成 500 看看其他不變,repartition(500)
(3)執行時間 :
17:09:03 ~ 17:17:47 , 8 分鐘
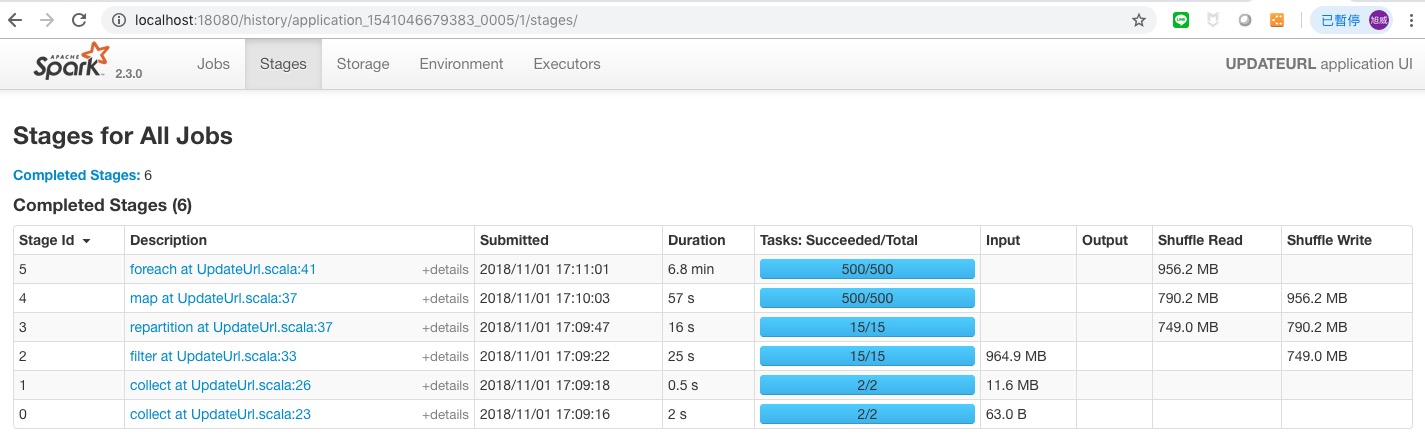
看來 partition 切到一個大小速度就上不去了.在執行的過程中其實 RUNNING 的 task 只有約 50 個在執行. 有可能跟 Containers 的資源大小有關,可以在測測.
接下來把 foreach 改成 foreachPartition 試試看 :
sc.textFile(inDir).map { str =>
...
}.filter(
...
).reduceByKey(
...
).repartition(500)
.map { case (id, person) =>
...
}.reduceByKey(
...
).foreachPartition { case (id, person) =>
...
}
執行 “update.sh” 測試 :
(1)spark-submit 參數 :
yarn cluster mode , driver-memory 9g , driver-cores 12 , executor-memory 14g(15g會超過) , executor-cores 10 , num-executors 5
(2)yarn 執行狀態 :
Containers Running : 6 個 , Memory Used : 90.66 GB , VCores Used : 72 core
spark 執行狀態 :
executors : 5 個 executor + 1 個 driver
Task : 500 個(實際同時 running 的只有 50 個左右)
executor-cores : 10 Cores
driver : 5G
(3)執行時間 :
18:03:52 ~ 18:10 , 7 分鐘
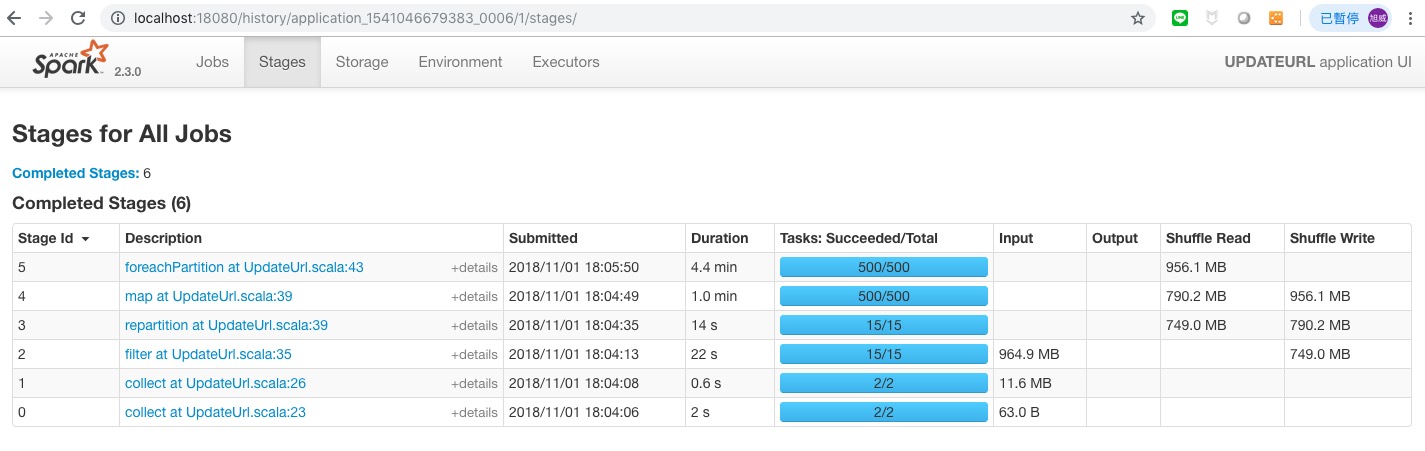
在這邊的案例使用 foreachPartition 筆 foreach 快了 2 分鐘左右.
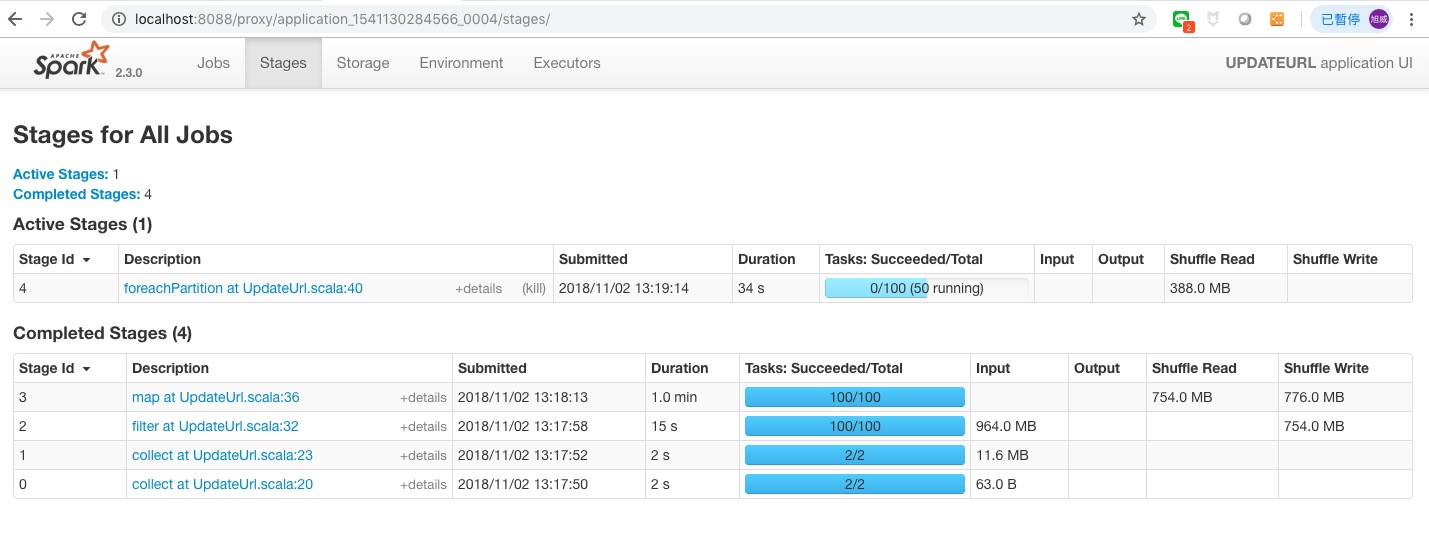
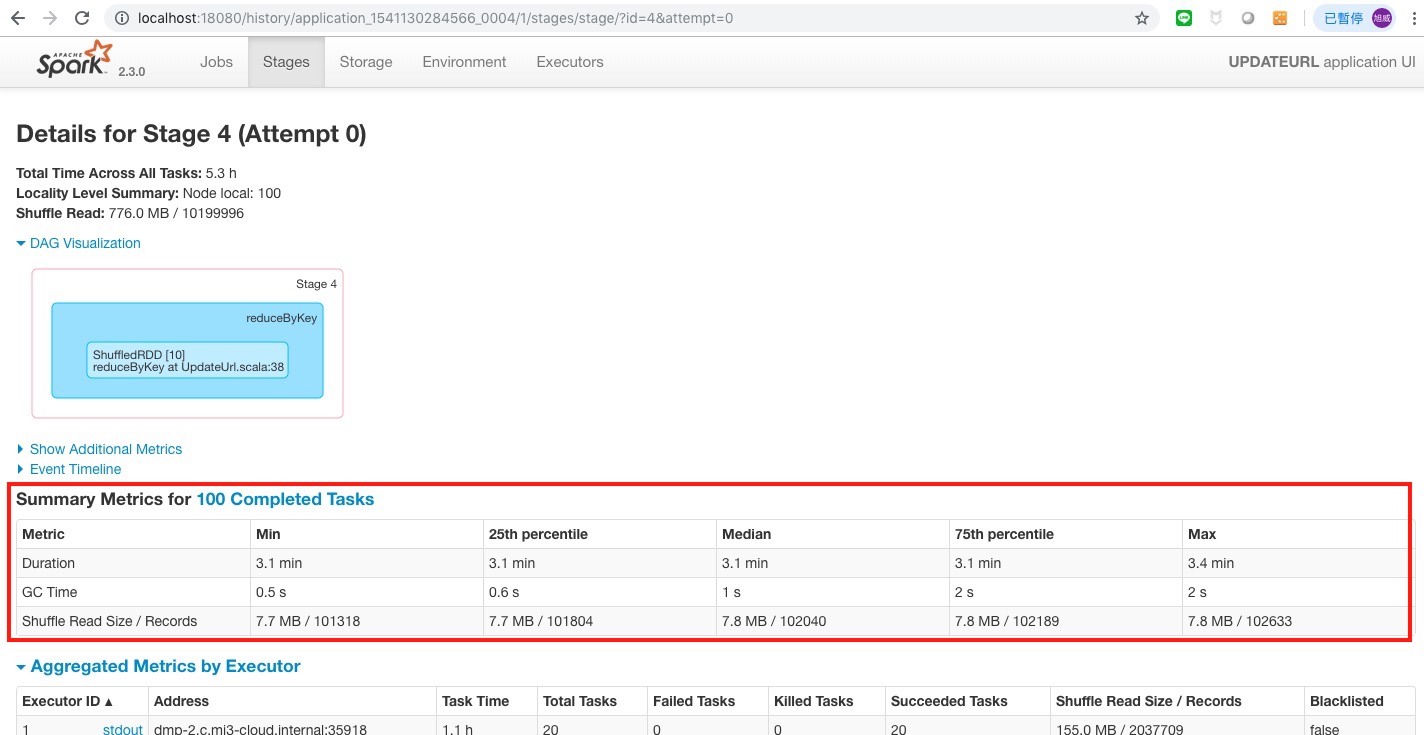
不管怎麼測,實際 RUNNING 的 task 上限大概是 50 左右,可能要再加大 excutoer 的 core 跟 memory 才可以再提升 RUNNING 的 task 數.
繼續提升機器規格做測試,一台機器的規格
32 Core , 120G
Hadoop Cluster 規格,每一台保留 6 Core 及 20G 的 Memory 給系統使用 :
Memory Total 100 GB
VCores Total 26
重新定義 yarn 的參數 yarn-site.xml :
yarn.scheduler.maximum-allocation-mb : 307200/3 = 102400 = 100G
yarn.scheduler.minimum-allocation-mb : 307200/12 = 25600 = 25 G
yarn.scheduler.maximum-allocation-vcores : 26/3 = 8 Core
yarn.scheduler.minimum-allocation-vcores : 26/13 = 2 Core
yarn.nodemanager.resource.memory-mb : 1024 * 100 = 102400
yarn.nodemanager.resource.cpu-vcores : 26 Core
執行 “update.sh” 測試 :
(1)spark-submit 參數 :
yarn cluster mode , driver-memory 20g , driver-cores 6 , executor-memory 8g , executor-cores 6 , num-executors 11
(2)yarn 執行狀態 :
Containers Running : 12 個 , Memory Used : 300 GB , VCores Used : 72 core
spark 執行狀態 :
executors : 11 個 executor + 1 個 driver
executor-cores : 6 Cores
(3)執行時間 :
11:04:05 ~ 11:13:26 , 9 分鐘
(4)redis 資料 : 20399991 筆左右
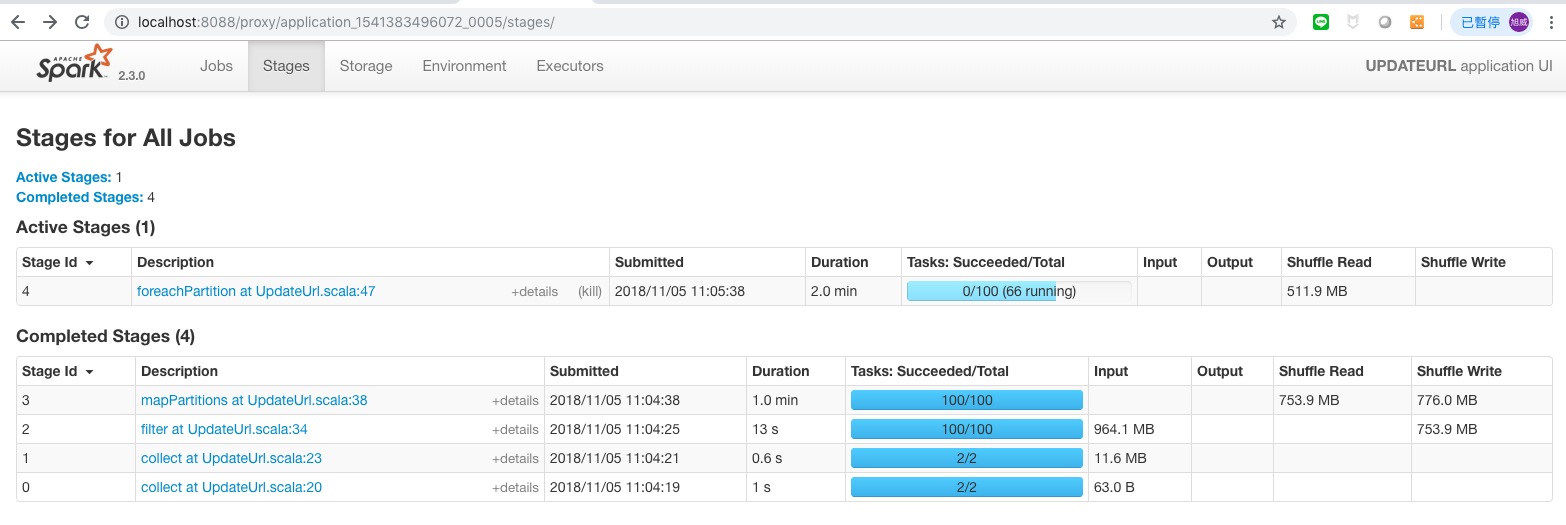
資源加大後提升到最多可以有 66 個 Task 同時在 RUNNING.
調整 GC
在 spark-defaults.conf 加上參數
spark.executor.extraJavaOptions -XX:+UseG1GC
沒有使用 G1GC 的時間 :
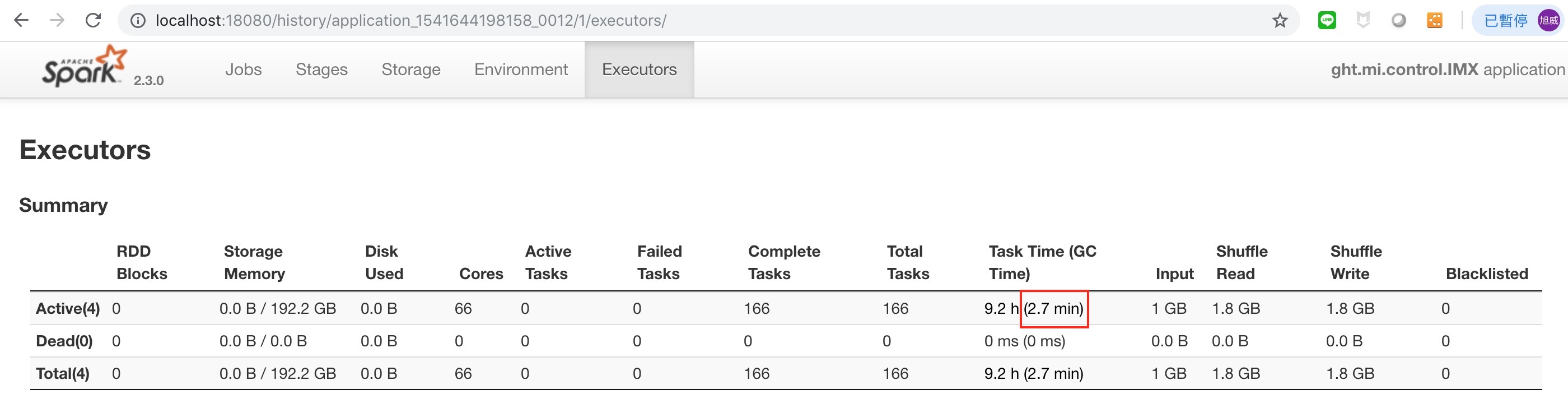
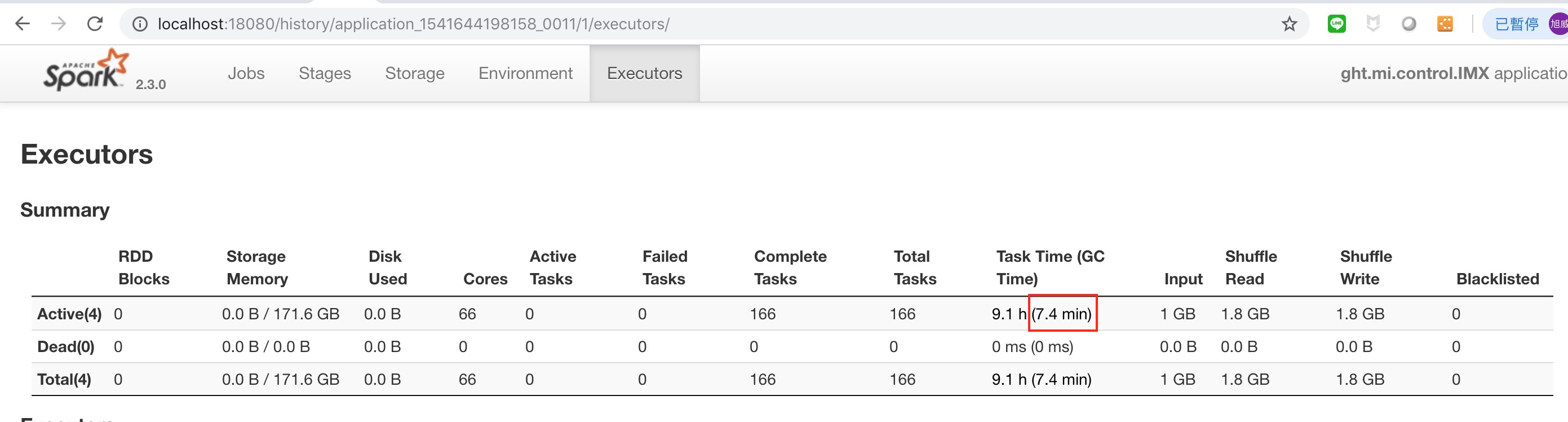 調整後的時間 :
調整後的時間 :
KryoSerializer
改成使用 KryoSerializer,並將自定義的 class registerKryoClasses :
val conf = new SparkConf()
conf.set("spark.sql.warehouse.dif", "/tmp")
conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
conf.registerKryoClasses(
Array(classOf[Person], classOf[Location], classOf[LatLon], classOf[Visit], classOf[Url], classOf[Url])
)
調高 JedisCluster 的 Connection 上限(預設是 8)
val jedisClusterNodes = new HashSet[HostAndPort]()
config.split(',').foreach { str =>
val Array(ip, _port) = str.split(':')
jedisClusterNodes.add(new HostAndPort(ip, _port.toInt))
}
val cpcfg = new GenericObjectPoolConfig()
cpcfg.setMaxTotal(10000)
cpcfg.setMaxIdle(10000)
val jc = new JedisCluster(jedisClusterNodes ,5000,5000,20,
AesUtil.decrypt(keyDir.split(",")(1) ,keyDir.split(",")(0)) , cpcfg)
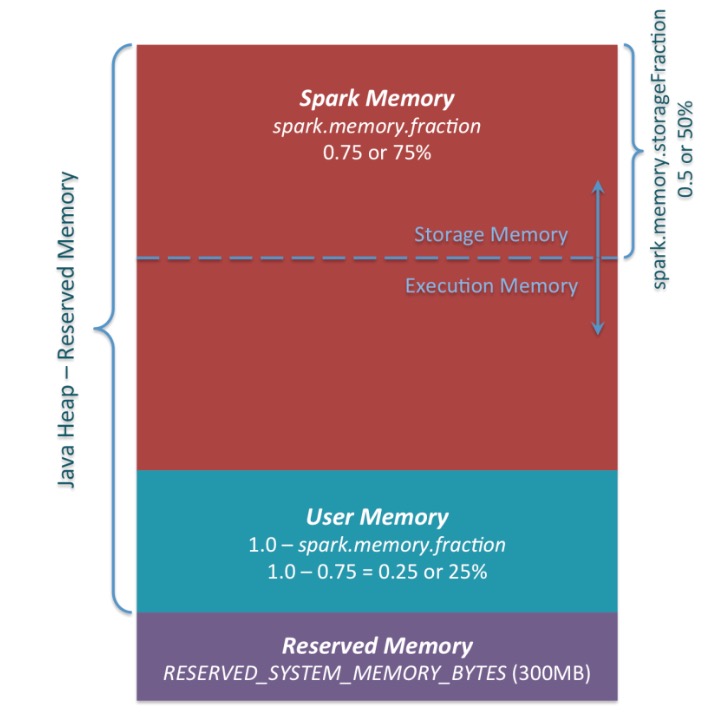
spark.memory.fraction
所以調整 performance 的重點整理
1. 程式寫法及 API 的使用
2. task 數量的調整
3. core 及 memory 的分配
一些心得 :
1. executer 的 core 數影響到可以跑的 task 數量,1 個 core 大概開 1 個 task 左右,task 數量介於 (core 數 * 1)
2. yarn 在算 memory 時會影響到實際能開多少個 container,所以雖然 num-executors 可能開 5 個,但資源沒開好,可能最後只會有 4 個 container 在跑
3. (executer 數量少資源多) 開的 task 比 (executer 數量多資源少) 還多.所以實際 Runnig 的 task 越多效能越好.
4. 在 spark-defaults.conf 加上 spark.executor.extraJavaOptions -XX:+UseG1GC 指定使用 G1GC 可以縮短許多 GC 的時間.
5. 使用 yarn external shuffle service 提昇性能.
參考資料
performance skill
update HDFS block size
map & mapPartitions
yarn UI params
manager-cpu-yarn-cluster
external shuffle service
- 其他參考
一個 spark application 所使用的資源為:
cores = spark.driver.cores + spark.executor.cores * spark.executor.instances
memory = spark.driver.memory + spark.yarn.driver.memoryOverhead + (spark.executor.memory + spark.yarn.executor.memoryOverhead) * spark.executor.instances