hive jdbc dynamic partition
使用 hive jdbc dynamic 建立 partition 步驟
- 建立來源 table
- 建立 partition table
- 設定 hive 兩個參數
set hive.exec.dynamic.partition=true
set hive.exec.dynamic.partition.mode=nonstrict - 執行 insert select
實作
- create 來源 table (test.students)
Hive CLI 語法 :
create table if not exists test.students ( id string COMMENT 'students id' , name string COMMENT 'students name' , tel string COMMENT 'students tel' , job string COMMENT 'students job' ) row format DELIMITED fields terminated by ',' lines terminated by '\n' stored as TEXTFILEjava 程式 :
@Test public void createTableByRowFormatDelimitedStudentTest() { HiveQLBean hqlBean = new HiveQLBean(); hqlBean.setTableType(HiveQLBean.TableType.TEMPORARY); hqlBean.setTableName("test.students"); List<HiveColumnBean> columns = new ArrayList<HiveColumnBean>(); columns.add(new HiveColumnBean("id" , "string" , "students id")); columns.add(new HiveColumnBean("name" , "string" , "students name")); columns.add(new HiveColumnBean("tel" , "string" , "students tel")); columns.add(new HiveColumnBean("job" , "string" , "students job")); hqlBean.setColumns(columns); hqlBean.setRowFormat(HiveQLBean.RowFormat.DELIMITED); hqlBean.setFieldsSplit(","); hqlBean.setLinesSplit("\\n"); hqlBean.setFileFormat(HiveQLBean.FileFormat.TEXTFILE); util.createTableByRowFormatDelimited(hqlBean); } - 準備個測試資料檔案 /home/cloudera/daniel/students.txt 放在要執行 job 那台機器底下(這邊是vm cloudera quickstart) :
1,Daniel,29612736,PG 2,Sam,283747612,SD 3,Andy,39827162,PM 4,Lucy,73612536,SA 5,Jacky,47829184,PG 6,Ray,27361938,SD 7,Hank,28881936,RD 8,Rebbeca,238177758,PM 9,Lin,288376581,PG 10,Bella,33726485,PM 11,Molin,57635163,RD 12,YuAne,48572613,PG 13,Samuel,67562849,SD 14,Zdchen,58271647,SA - 將資料匯入來源 table (test.students)
Hive CLI 語法 :load data local inpath '/home/cloudera/daniel/students.txt' into table test.studentsjava 程式 :
@Test public void loadLocalDataIntoTableStudentTest() { String filepath = "/home/cloudera/daniel/students.txt"; String tableName = "test.students"; util.loadLocalDataIntoTable(filepath, tableName); } - create partition table 的語法 :
Hive CLI 語法 :create table if not exists test.students_partition ( id string COMMENT 'students id' , name string COMMENT 'students name' , tel string COMMENT 'students tel' ) partitioned by ( job string ) row format DELIMITED fields terminated by ',' lines terminated by '\n' stored as TEXTFILEjava 程式 :
@Test public void createTableByRowFormatDelimitedStudentPartitionedTest() { HiveQLBean hqlBean = new HiveQLBean(); hqlBean.setTableType(HiveQLBean.TableType.TEMPORARY); hqlBean.setTableName("test.students_partition"); List<HiveColumnBean> columns = new ArrayList<HiveColumnBean>(); columns.add(new HiveColumnBean("id" , "string" , "students id")); columns.add(new HiveColumnBean("name" , "string" , "students name")); columns.add(new HiveColumnBean("tel" , "string" , "students tel")); hqlBean.setColumns(columns); hqlBean.setRowFormat(HiveQLBean.RowFormat.DELIMITED); hqlBean.setFieldsSplit(","); hqlBean.setLinesSplit("\\n"); hqlBean.setFileFormat(HiveQLBean.FileFormat.TEXTFILE); List<HiveColumnBean> pcolumns = new ArrayList<HiveColumnBean>(); pcolumns.add(new HiveColumnBean("job" , "string" , "students job")); hqlBean.setPartitionedColumns(pcolumns); util.createTableByRowFormatDelimited(hqlBean); } -
使用 dynamic 建立 partition 要加下列兩個參數
set hive.exec.dynamic.partition=true
set hive.exec.dynamic.partition.mode=nonstrict - insert select 語法 :
Hive CLI 語法 :set hive.exec.dynamic.partition=true; set hive.exec.dynamic.partition.mode=nonstrict; INSERT INTO TABLE test.students_partition partition ( job ) select * from test.students;java 程式 :
@Test public void insertIntoSelectTableTest() { String insertTable = "test.students_partition"; List<HiveColumnBean> partitionedColumns = new ArrayList<HiveColumnBean>(); partitionedColumns.add(new HiveColumnBean("job" , "string" , "students job")); List<HiveColumnBean> selectColumns = new ArrayList<HiveColumnBean>(); String selectTable = "test.students"; List<HiveColumnBean> whereConditionColumns = new ArrayList<HiveColumnBean>(); util.setHiveConfProperties("hive.exec.dynamic.partition", "true"); util.setHiveConfProperties("hive.exec.dynamic.partition.mode", "nonstrict"); util.insertIntoSelectTable(insertTable, partitionedColumns, selectColumns, selectTable, whereConditionColumns); } - 如果 partition 數太多的話要再加上下列兩個參數,insert select 時跑 Map Reduce 時才不會出錯 : util.setHiveConfProperties(“hive.exec.max.dynamic.partitions”, “3000”); util.setHiveConfProperties(“hive.exec.max.dynamic.partitions.pernode”, “3000”);
注意事項
- 由於是透過沒有認證過的 user 對 hive 做操作,所以 hive 會用 anonymous 這 user 做操作 :

-
執行 insert select 會執行 hadoop 的 map reduce,在執行 map reduce 時,會需要在 hdfs 的 /user 底下有該 user 的目錄,所以要在這邊建立 anonymous 的目錄並修改權限 :
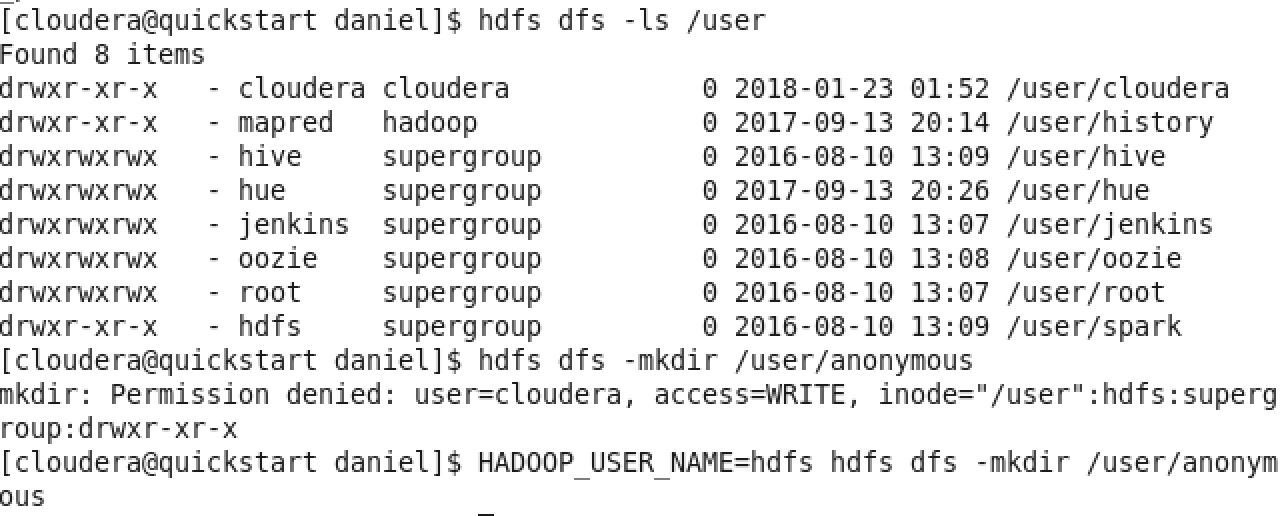
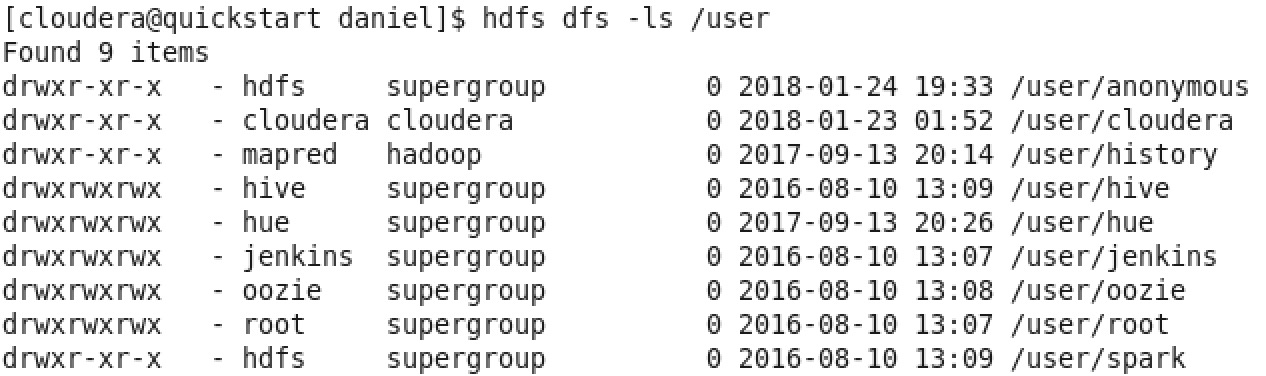
- 如果直接使用下列指令建立,會發生 Permission denied,因為 /user 是權限屬於 hdfs 該 user 的.
hdfs dfs -mkdir /user/anonymous - 這時候在指令前面再加上 HADOOP_USER_NAME=hdfs,指定 Hadoop 的 user 使用 hdfs 這 user 執行就可以了 :
HADOOP_USER_NAME=hdfs hdfs dfs -mkdir /user/anonymous
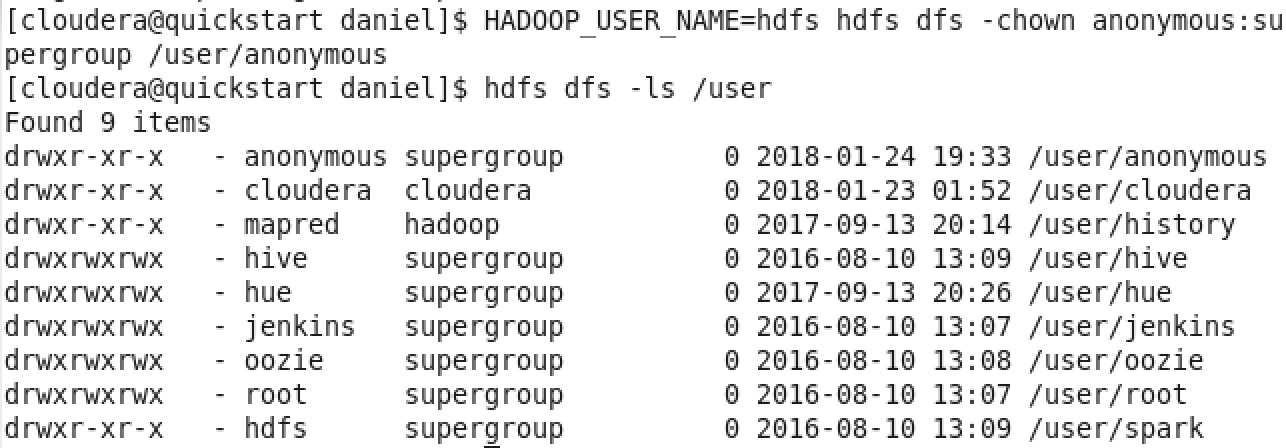
- 建好之後再把 user hdfs 改成 anonymous,指令如下 :
HADOOP_USER_NAME=hdfs hdfs dfs -chown anonymous:supergroup /user/anonymous
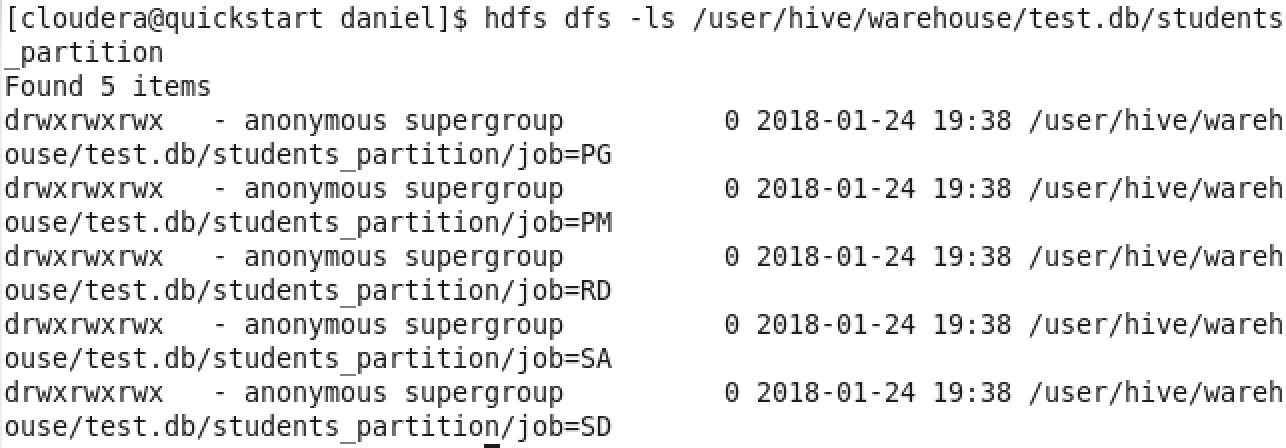
- dynamic 建立 partition 成功 :
- anonymous user 如果要換另外一個 user ,可用下列寫法,不用密碼給 user 就好了:
String url = "jdbc:hive2://quickstart.cloudera:10000/"; String userName = "abc"; String userPasswrd = ""; con = DriverManager.getConnection(url, userName, userPasswrd);
總結
- 在執行 hadoop 的 map reduce 時,會需要在 hdfs 的 /user 底下有該 user 的目錄,要確認否則跑 map reduce 的 job 時會失敗.錯誤訊息如下 :
[18/01/25 12:47:09][ERROR][com.hadoopetl.hive.util.HiveMetaUtil-654] Error while processing statement: FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask
java.sql.SQLException: Error while processing statement: FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask
at org.apache.hive.jdbc.HiveStatement.execute(HiveStatement.java:279)
at org.apache.hive.jdbc.HiveStatement.executeUpdate(HiveStatement.java:389)
at org.apache.hive.jdbc.HivePreparedStatement.executeUpdate(HivePreparedStatement.java:119)
at com.hadoopetl.db.HiveDbDao.executeUpdate(HiveDbDao.java:73)
at com.hadoopetl.hive.util.HiveMetaUtil.insertSelectTable(HiveMetaUtil.java:652)
at com.hadoopetl.hive.util.HiveMetaUtil.insertIntoSelectTable(HiveMetaUtil.java:398)
at com.hadoopetl.hive.util.test.HiveMetaUtilTest.insertIntoSelectTableTest(HiveMetaUtilTest.java:146)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:606)
at org.junit.runners.model.FrameworkMethod$1.runReflectiveCall(FrameworkMethod.java:50)
at org.junit.internal.runners.model.ReflectiveCallable.run(ReflectiveCallable.java:12)
at org.junit.runners.model.FrameworkMethod.invokeExplosively(FrameworkMethod.java:47)
at org.junit.internal.runners.statements.InvokeMethod.evaluate(InvokeMethod.java:17)
at org.junit.internal.runners.statements.RunBefores.evaluate(RunBefores.java:26)
at org.junit.runners.ParentRunner.runLeaf(ParentRunner.java:325)
at org.junit.runners.BlockJUnit4ClassRunner.runChild(BlockJUnit4ClassRunner.java:78)
at org.junit.runners.BlockJUnit4ClassRunner.runChild(BlockJUnit4ClassRunner.java:57)
at org.junit.runners.ParentRunner$3.run(ParentRunner.java:290)
at org.junit.runners.ParentRunner$1.schedule(ParentRunner.java:71)
at org.junit.runners.ParentRunner.runChildren(ParentRunner.java:288)
at org.junit.runners.ParentRunner.access$000(ParentRunner.java:58)
at org.junit.runners.ParentRunner$2.evaluate(ParentRunner.java:268)
at org.junit.runners.ParentRunner.run(ParentRunner.java:363)
at org.eclipse.jdt.internal.junit4.runner.JUnit4TestReference.run(JUnit4TestReference.java:86)
at org.eclipse.jdt.internal.junit.runner.TestExecution.run(TestExecution.java:38)
at org.eclipse.jdt.internal.junit.runner.RemoteTestRunner.runTests(RemoteTestRunner.java:459)
at org.eclipse.jdt.internal.junit.runner.RemoteTestRunner.runTests(RemoteTestRunner.java:678)
at org.eclipse.jdt.internal.junit.runner.RemoteTestRunner.run(RemoteTestRunner.java:382)
at org.eclipse.jdt.internal.junit.runner.RemoteTestRunner.main(RemoteTestRunner.java:192)
-
hive create table 時,如果有指令 location 時或著create external takbe,/user/hive/warehouse 底下就不會產生資料,drop table 如果是用 internal + loacation 時 /tmp/daniel/hivefile 的目錄整個會被刪掉.如果是 external table 就不會被刪掉.
-
檔案欄位比table多時資料好像不會擠到同一個欄位,是多的欄位就pareser不到了,不會顯示.但檔案欄位比table少的,會顯示 null