使用 intelliJ run scala unit test
build.sbt
libraryDependencies += "org.scalatest" %% "scalatest" % "3.0.5" % "test"
run unit test
- 在 /src/test/scala/ 裡增加測試的 scala class 及 test function,然後在 function 按右鍵
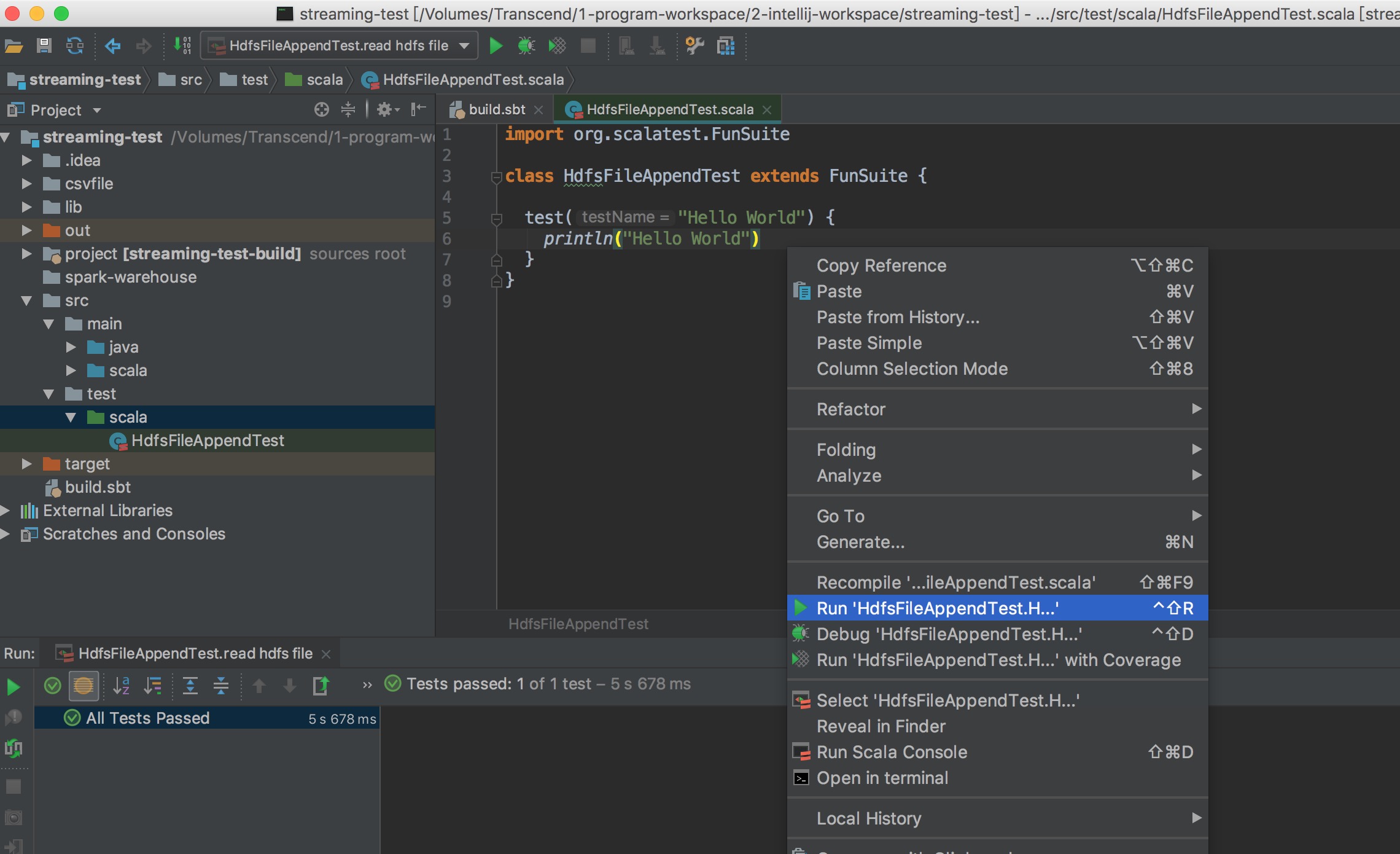
- HdfsFileAppendTest.scala 需 extends FunSuite
import org.scalatest.FunSuite
class HdfsFileAppendTest extends FunSuite {
test("Hello World") {
println("Hello World")
}
}
讀取 csv files
test("read csv files") {
val userSchema = new StructType()
.add("TagName", "string")
.add("TimeStamp", "string")
.add("Min", "integer")
.add("Max", "integer")
.add("Avg", "double")
val spark = SparkSession
.builder
.appName("Spark-csv")
.master("local[2]")
.getOrCreate()
val csvDF = spark.read
.option("header","true")
.schema(userSchema)
.csv("/Volumes/Transcend/1-program-workspace/2-intellij-workspace/streaming-test/csvfile")
csvDF.foreach(row => println(row))
}
讀取 hdfs 上的檔案
test("read hdfs file") {
val spark = SparkSession
.builder
.appName("Spark-csv")
.master("local[2]")
.getOrCreate()
val file = spark.sparkContext.textFile("hdfs://192.168.61.105/tmp/streaming-test/file_1/part-00000")
file.foreach(println(_))
}
寫入 hdfs 產生 csv 檔(case class + toDF)
import org.apache.spark.sql.{SaveMode, SparkSession}
import org.apache.spark.sql.types.StructType
import org.scalatest.FunSuite
class HdfsFileAppendTest extends FunSuite {
test("gen hdfs csv files") {
val spark = SparkSession
.builder
.appName("Spark-csv")
.master("local[2]")
.getOrCreate()
import spark.implicits._
val df = Seq(Person("Daniel" , 22),Person("Sam",18)).toDF().coalesce(1)
df.write.mode(SaveMode.Overwrite).csv("hdfs://192.168.61.105/tmp/streamingtest/test")
}
}
//記得要放在外面放在 test function 或 test class 裡會出錯
case class Person(name: String, age: Int)
[root@daniel-3-test-master1 ~]# hdfs dfs -cat /tmp/streamingtest/test/part-00000-eb1d2cd8-3300-457b-a442-4ccd72c3f150-c000.csv
Daniel,22
Sam,18
spark 中使用 createDataFrame 建立 DataFrame
test("spark createDataFrame") {
import org.apache.spark.sql.types._
val schema = StructType(List(
StructField("name", StringType, nullable = false),
StructField("age", IntegerType, nullable = true)
))
val spark = SparkSession
.builder
.appName("Spark-csv")
.master("local[2]")
.getOrCreate()
import collection.JavaConversions._
val rdd = Seq(
Row("Daniel" , 22),
Row("Sam",18)
)
val df = spark.createDataFrame(rdd , schema)
df.foreach(row => println(row.getAs[String]("name") + " , " + row.getAs[String]("age") ))
}
read hdfs csv files
test("read hdfs csv files") {
val schema = StructType(List(
StructField("name", StringType, nullable = false),
StructField("age", IntegerType, nullable = true)
))
val spark = SparkSession
.builder
.appName("Spark-csv")
.master("local[2]")
.getOrCreate()
val csvDF = spark.read
.schema(schema)
.csv("hdfs://192.168.61.105/tmp/streamingtest/test")
csvDF.foreach(row => println(row))
}
參考資料
scala unit test
dataframe 參考