Scala day 33 (sbt-assembly)
如何使用 sbt-assembly build 出包含 dependency 的 fat jar
- 準備一個 project,並寫一隻 wordcount :
package com.example.job
import org.apache.spark._
object WordCount {
def main(args: Array[String]): Unit = {
// create Spark context with Spark configuration
val sc = new SparkContext(new SparkConf().setMaster("local[2]").setAppName("Spark Count"))
// read in text file and split each document into words
val tokenized = sc.textFile(args(0)).flatMap(_.split(" "))
// count the occurrence of each word
val wordCounts = tokenized.map((_, 1)).reduceByKey(_ + _)
System.out.println(wordCounts.collect().mkString(", "))
}
}
- 在 project 底下建立 assembly.sbt,還有專案的根目錄建立一個 assembly.sbt
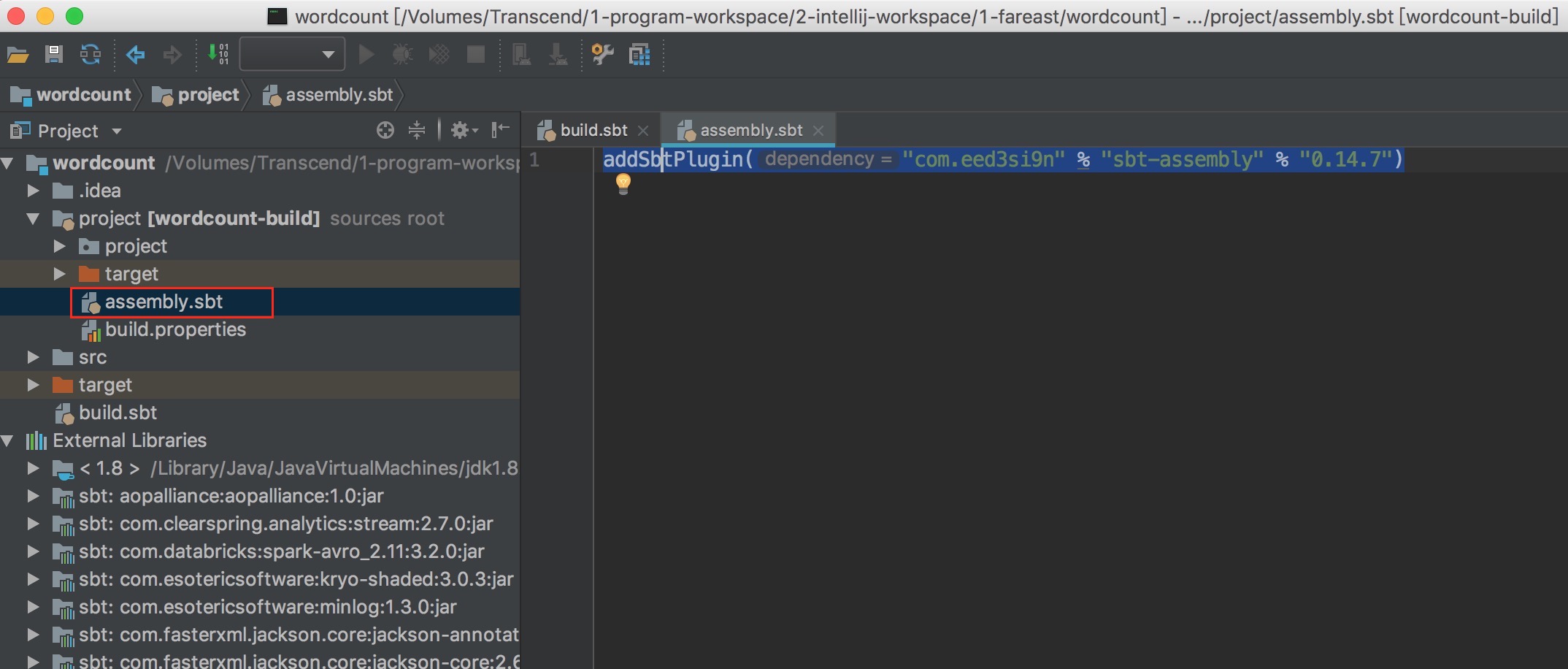
- 在 project 底下的 assembly.sbt 加上 :
addSbtPlugin("com.eed3si9n" % "sbt-assembly" % "0.14.7")
- 先下 sbt :
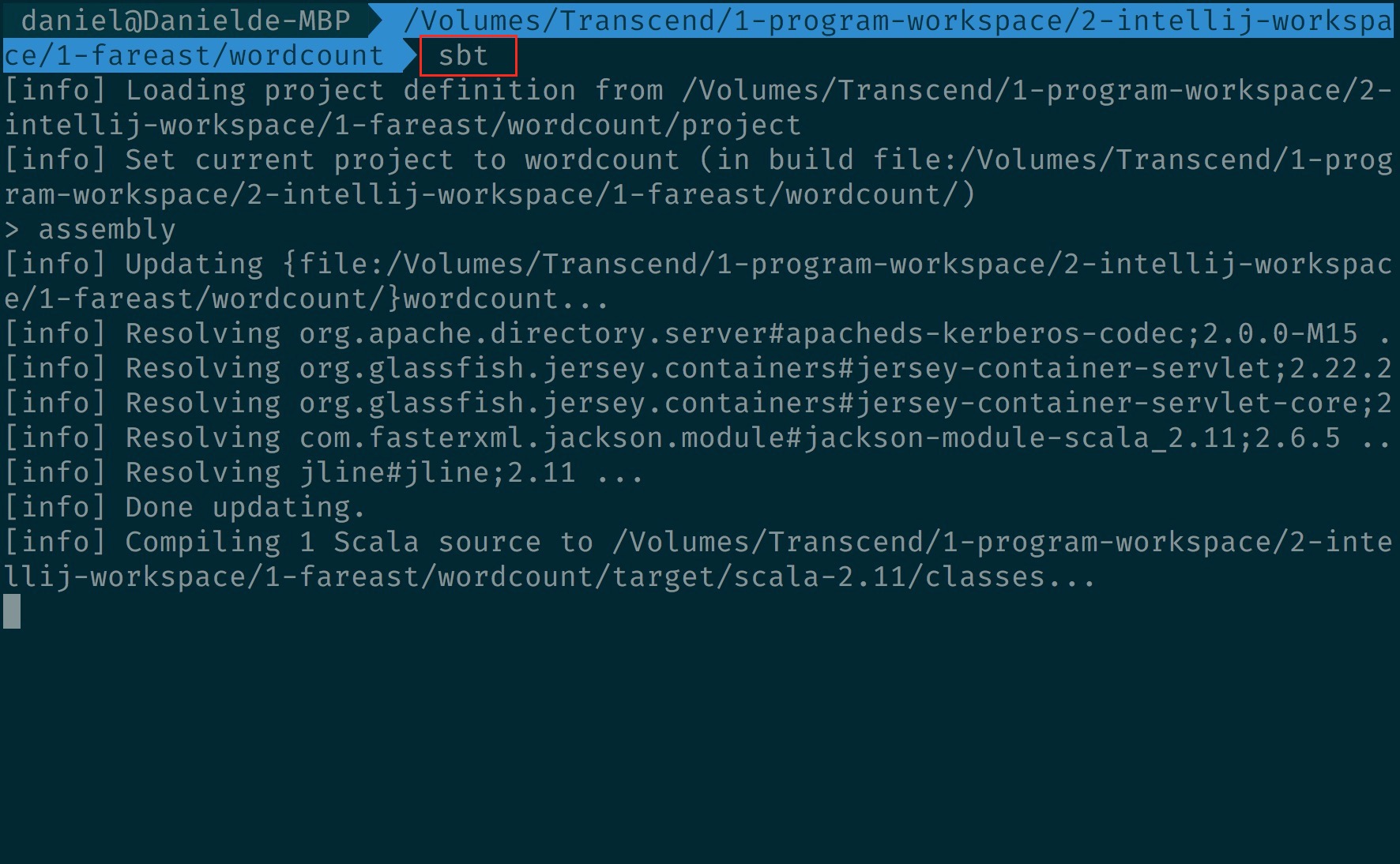
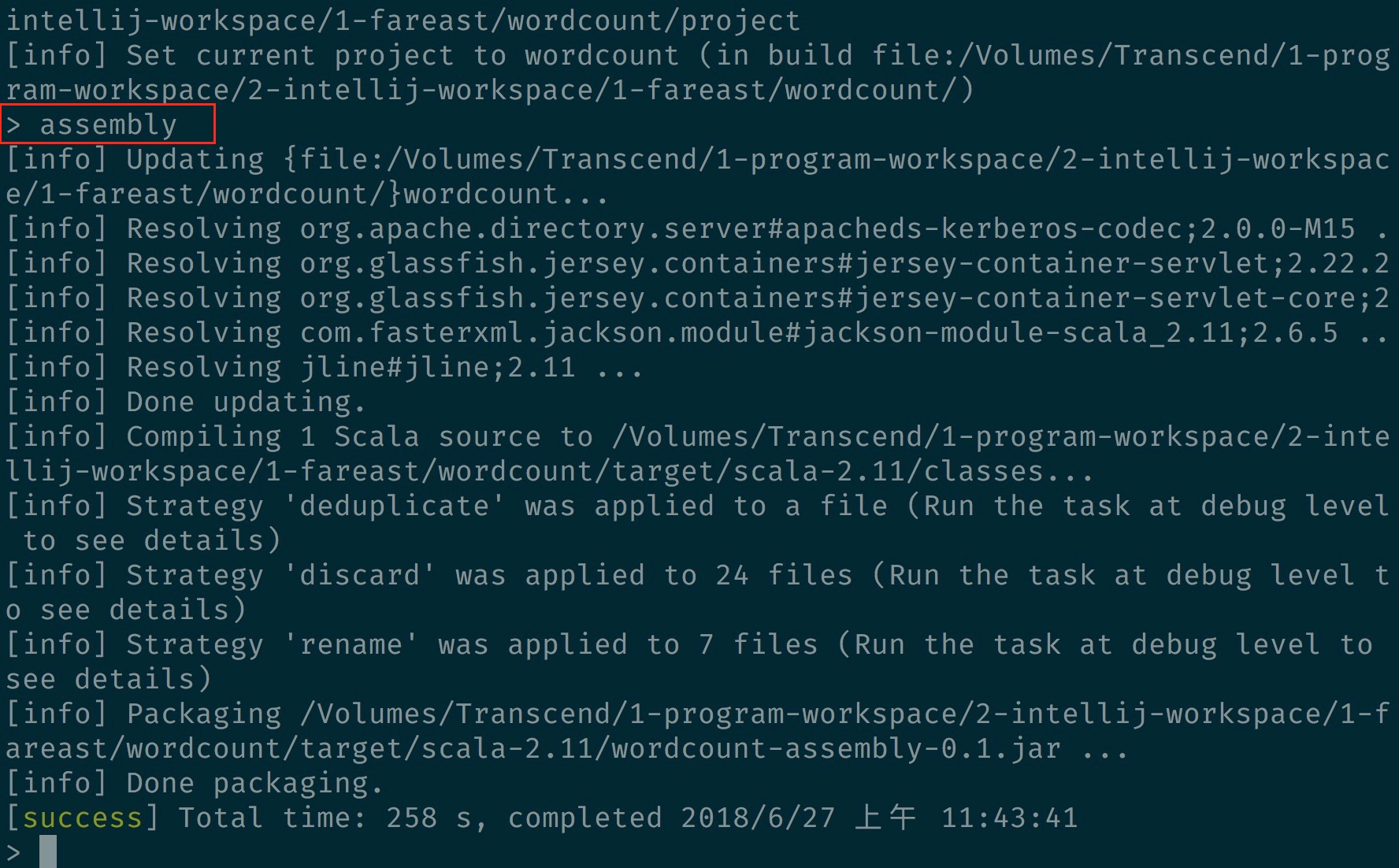
- 再下 assembly 打包 :
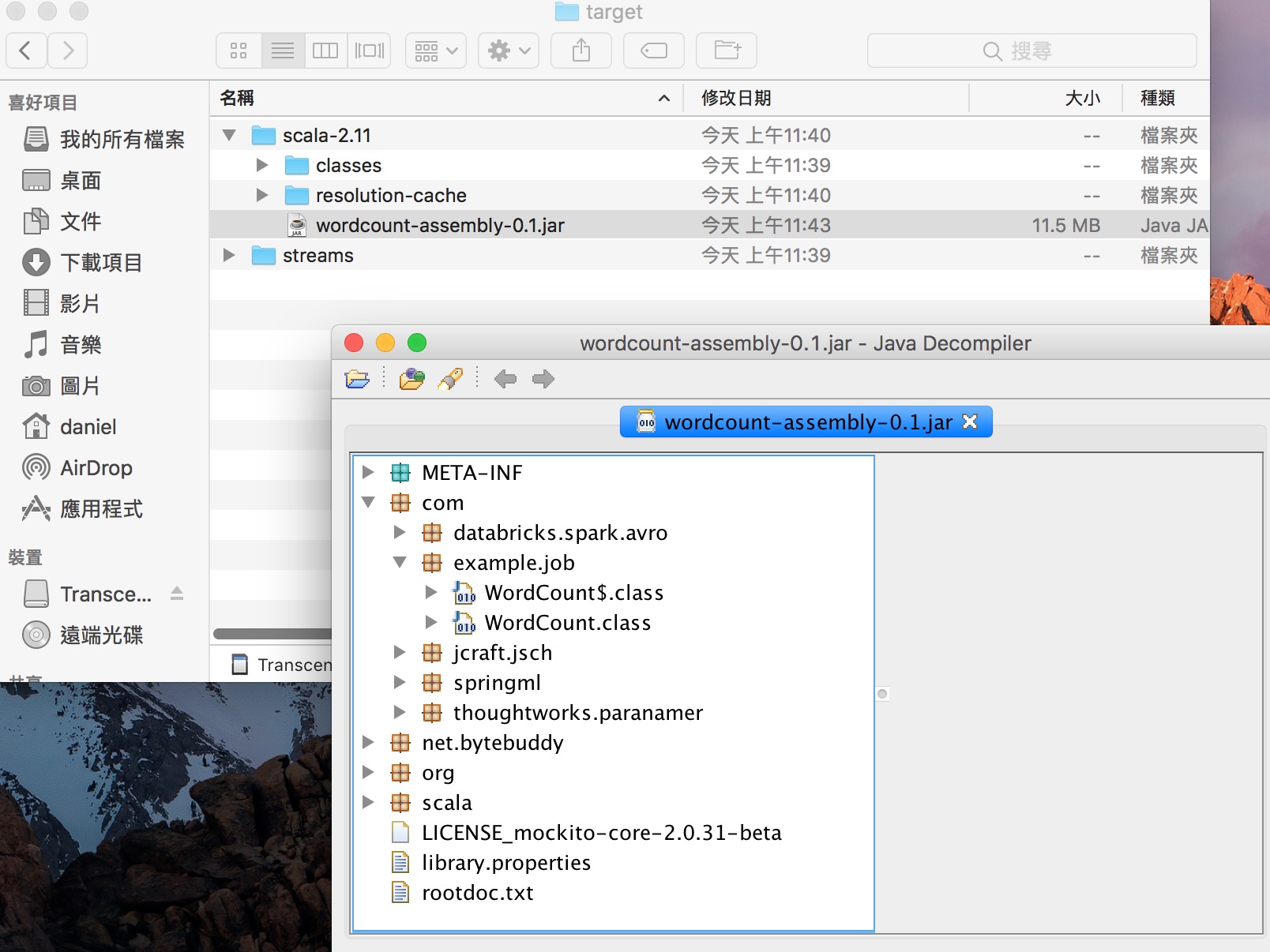
- 會看到相依的 jar 的 class 也都有打包進去 :
-
build.sbt 裡如果有加上 provided 代表不用打包到 jar 裡
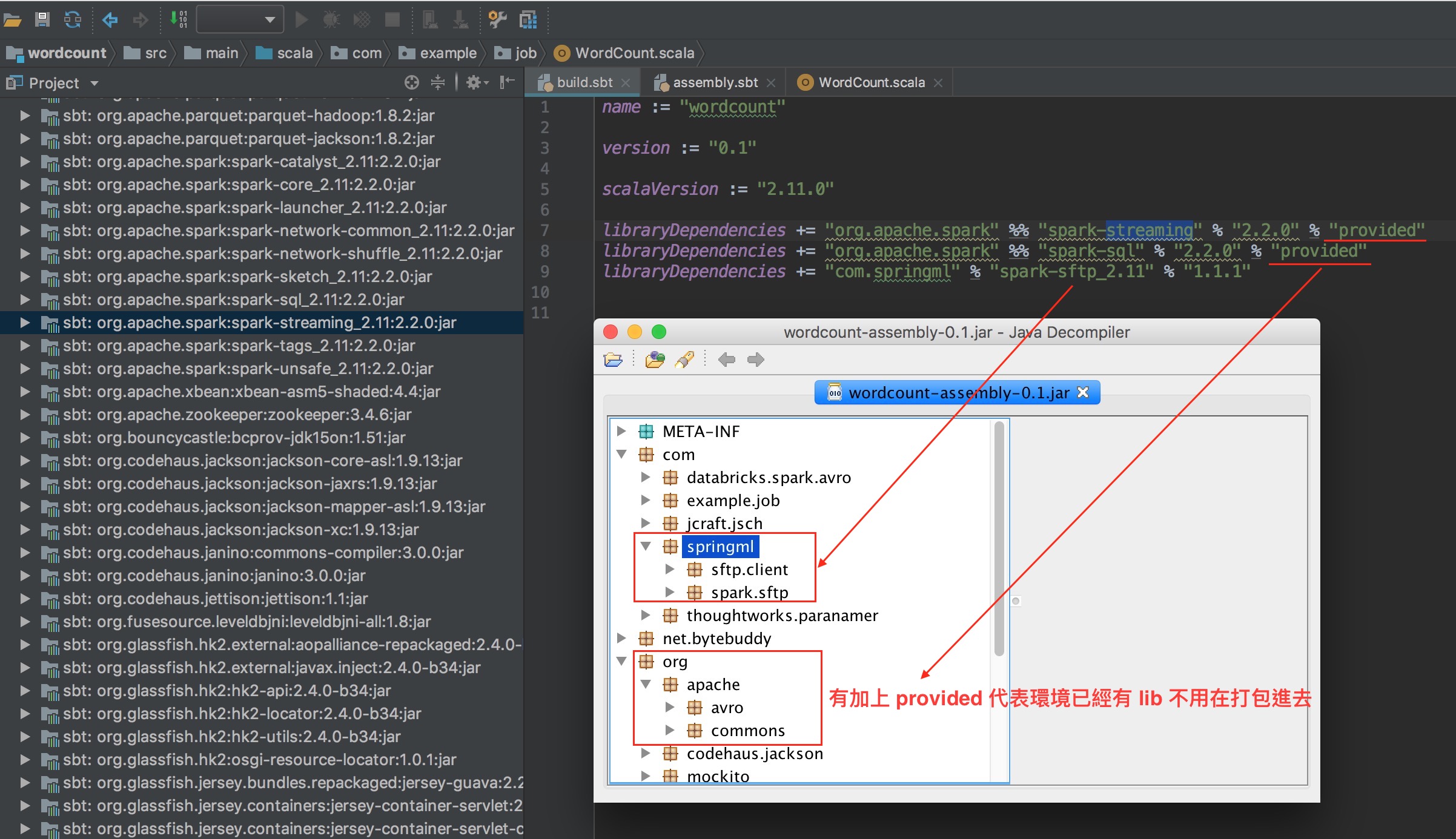
-
使用版本 :
- build 好之後,可以 scp 把 jar 丟到某台叢集上,然後下 spark2-submit.這邊給路徑是 HDFS 的路徑
spark2-submit --class com.example.job.WordCount --master yarn wordcount.jar /tmp/wordcount-test/news.txt - 這邊給的路徑是 local 的路徑
spark2-submit --class com.example.job.WordCount --master yarn wordcount.jar file:///tmp/wordcount-test/news.txt -
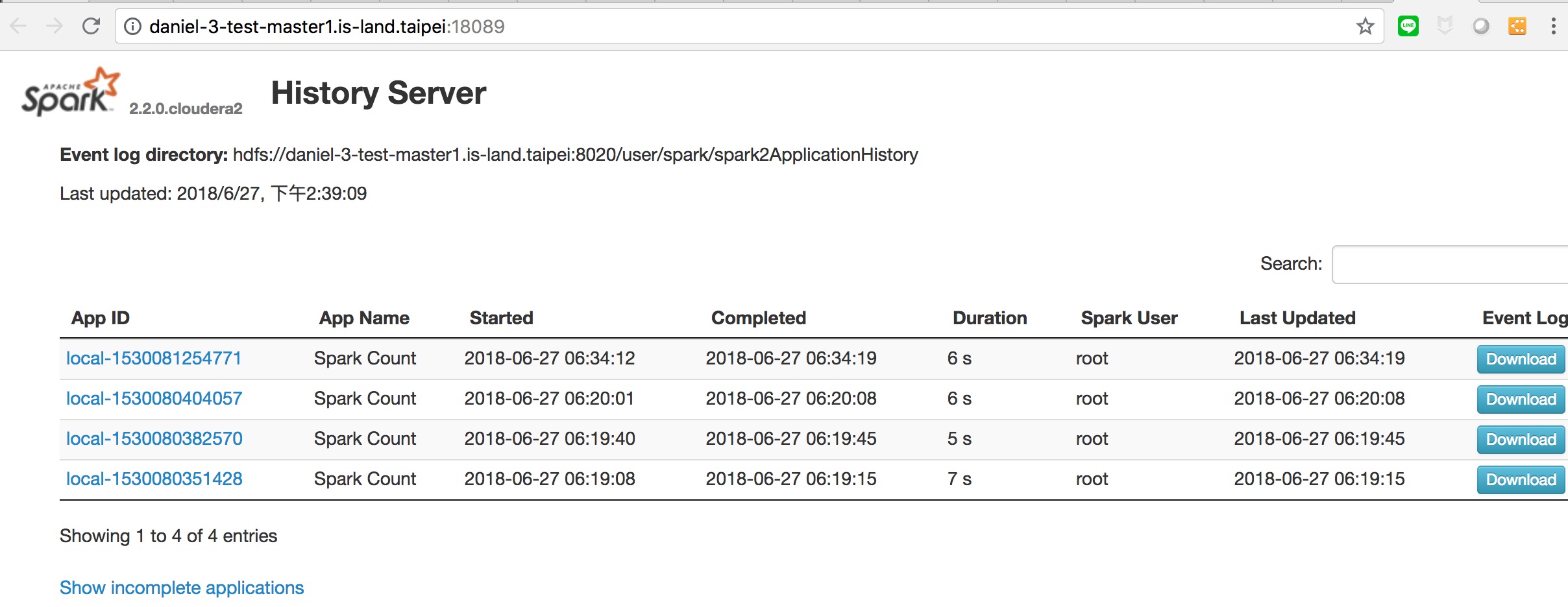
將 job 送到 spark 自己的環境執行
- 將 job 送到 yarn 上面執行,需先將程式裡的 .setMaster(“local[2]”) 拿掉.不然下 spark2-submit 指定 –master yarn 也是沒有用,還是會送到 spark 自己的環境執行
val sc = new SparkContext(new SparkConf().setMaster("local[2]").setAppName("Spark Count"))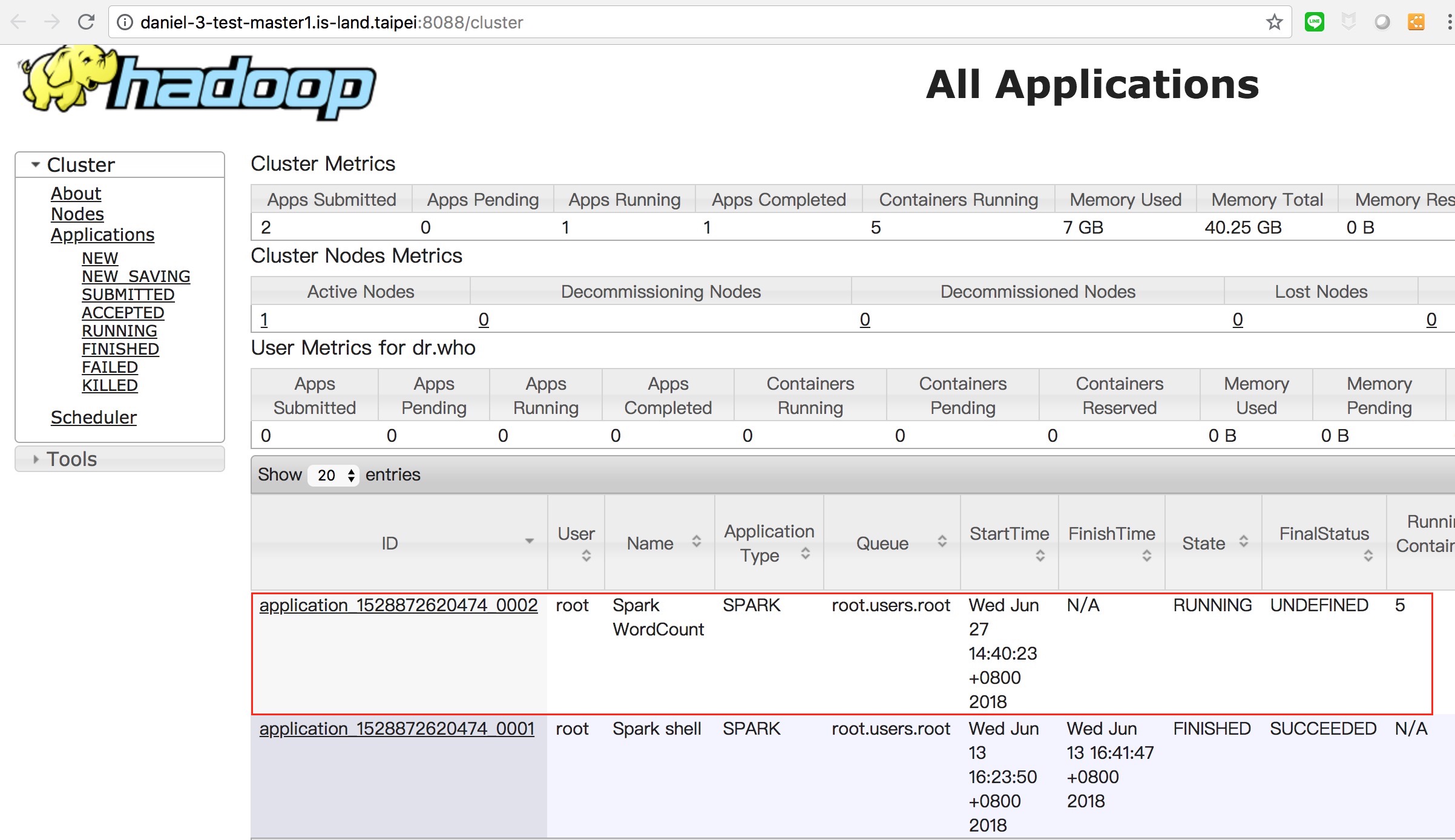
參考資料 :
sbt-assembly