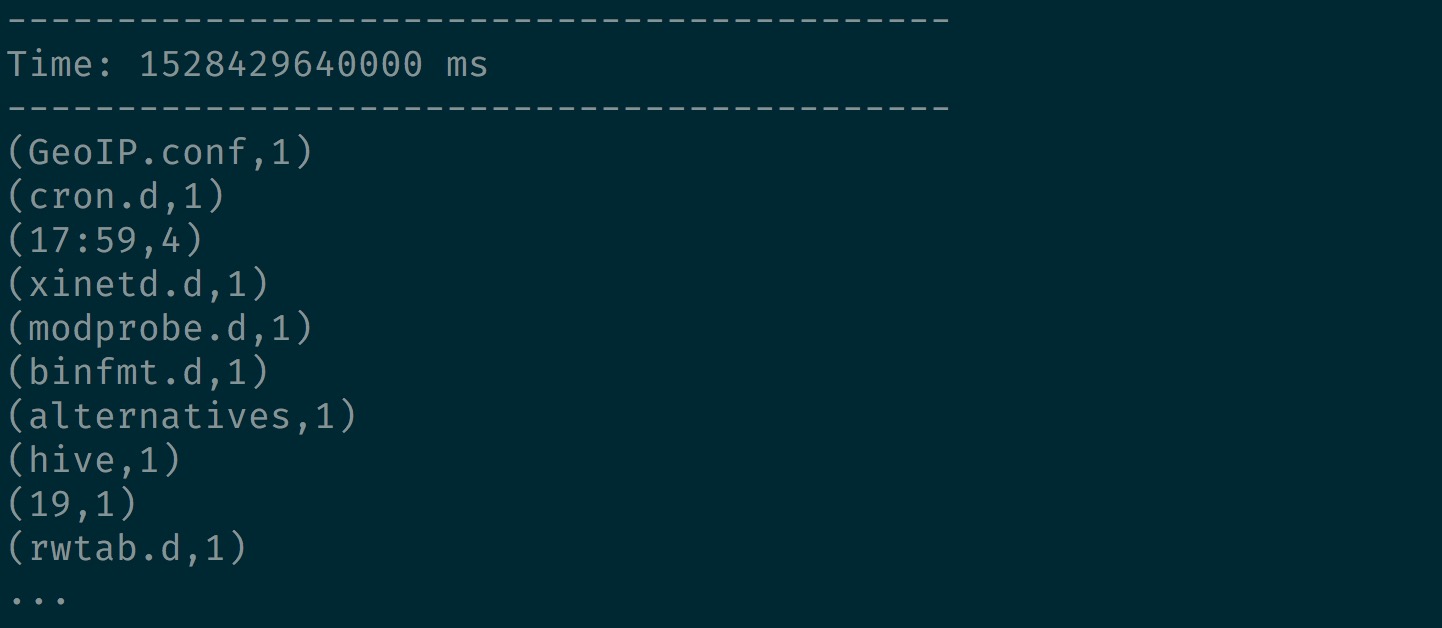
Spark-Streaming day 2 (intelliJ Hello World)
目標
使用 intelliJ 開發一個 Hello World 程式
install scala plugin

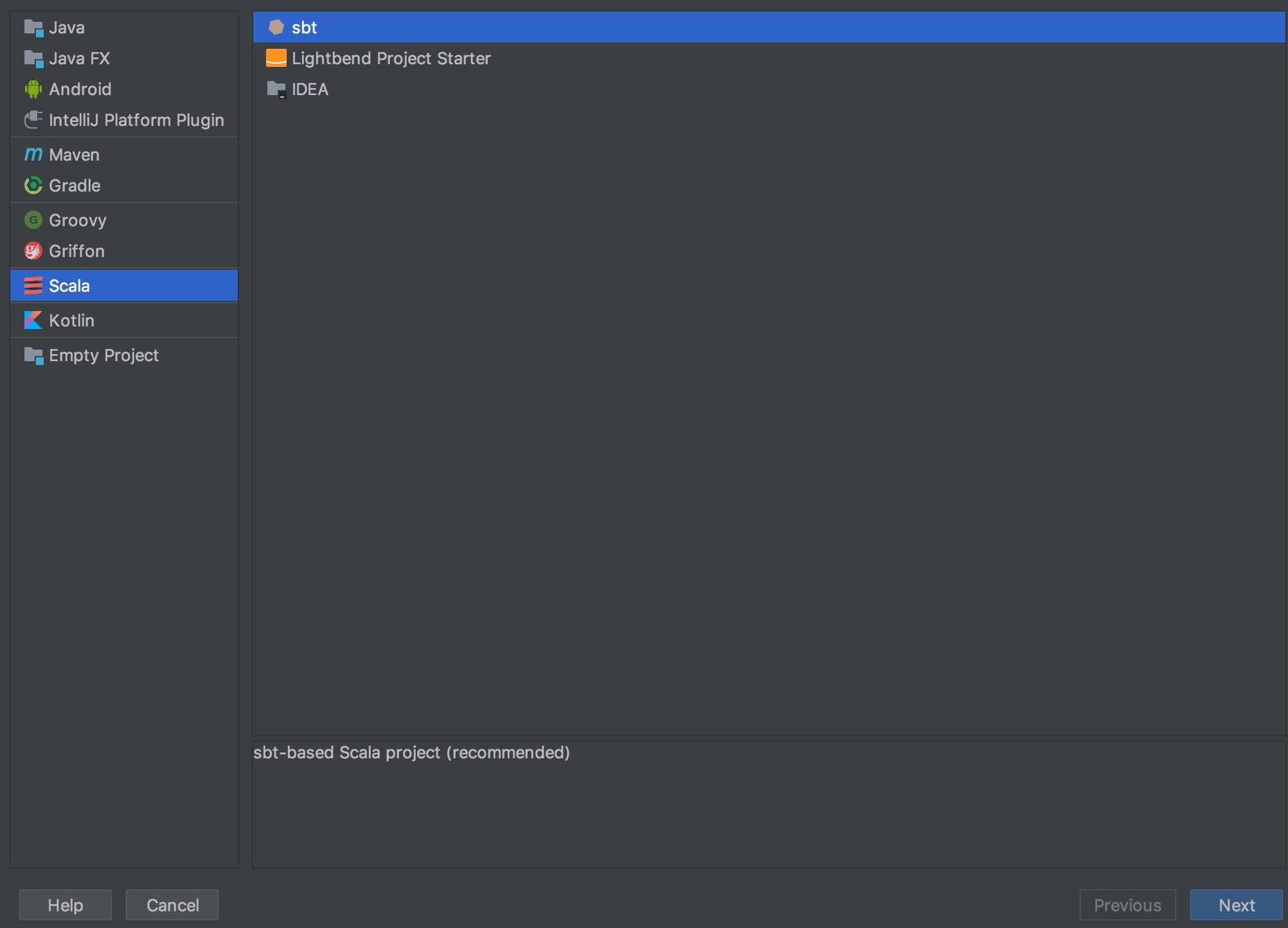
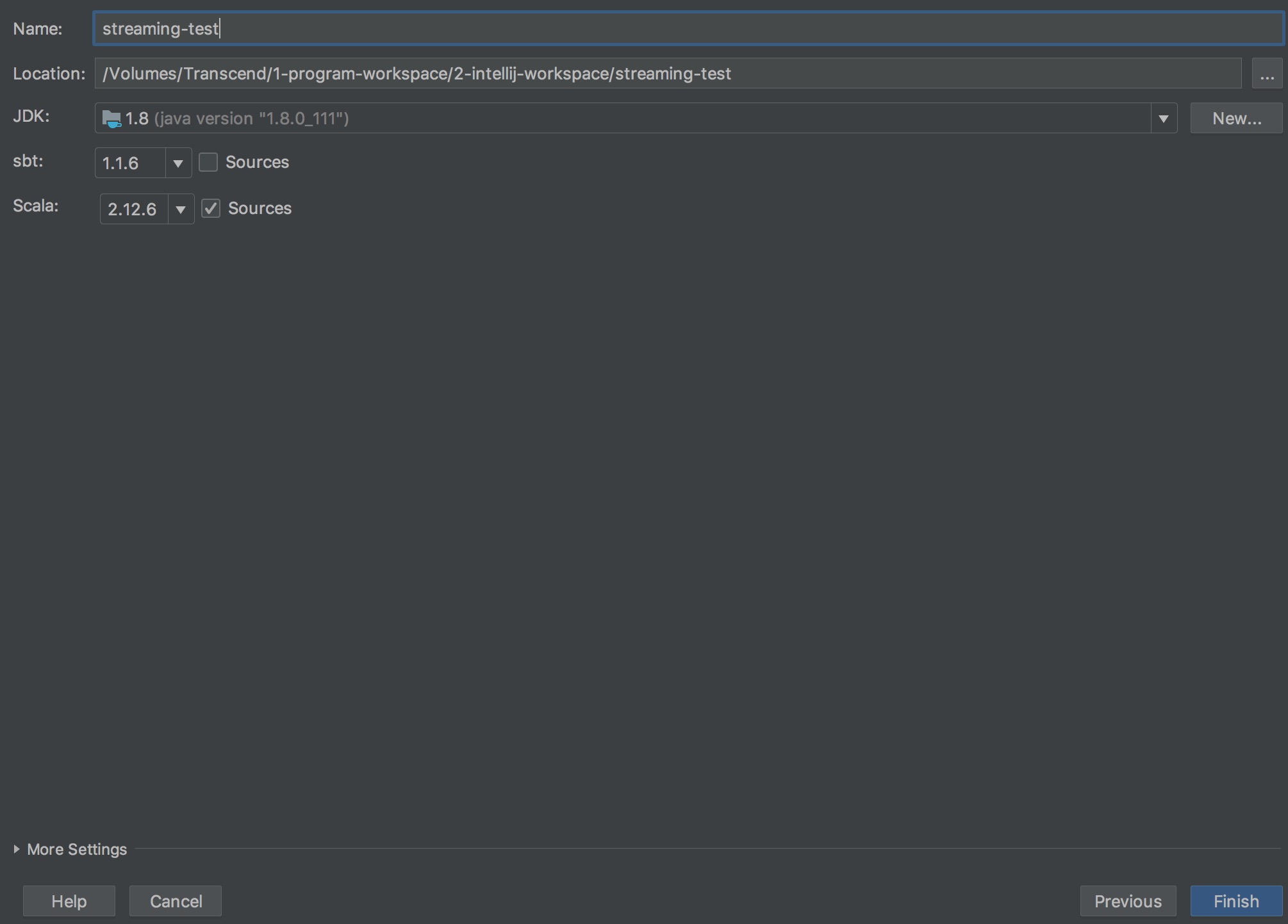
建立一個新的 project

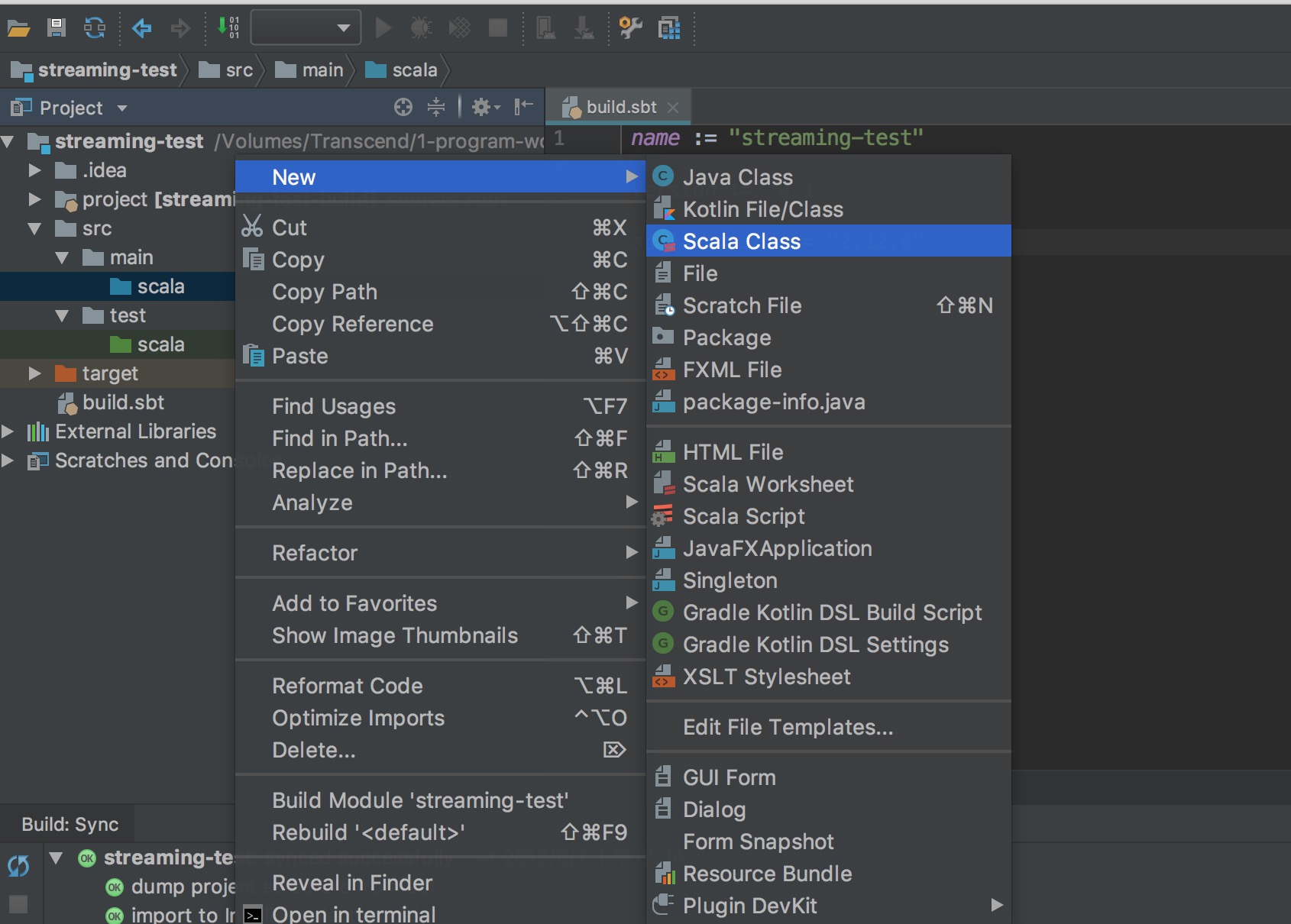
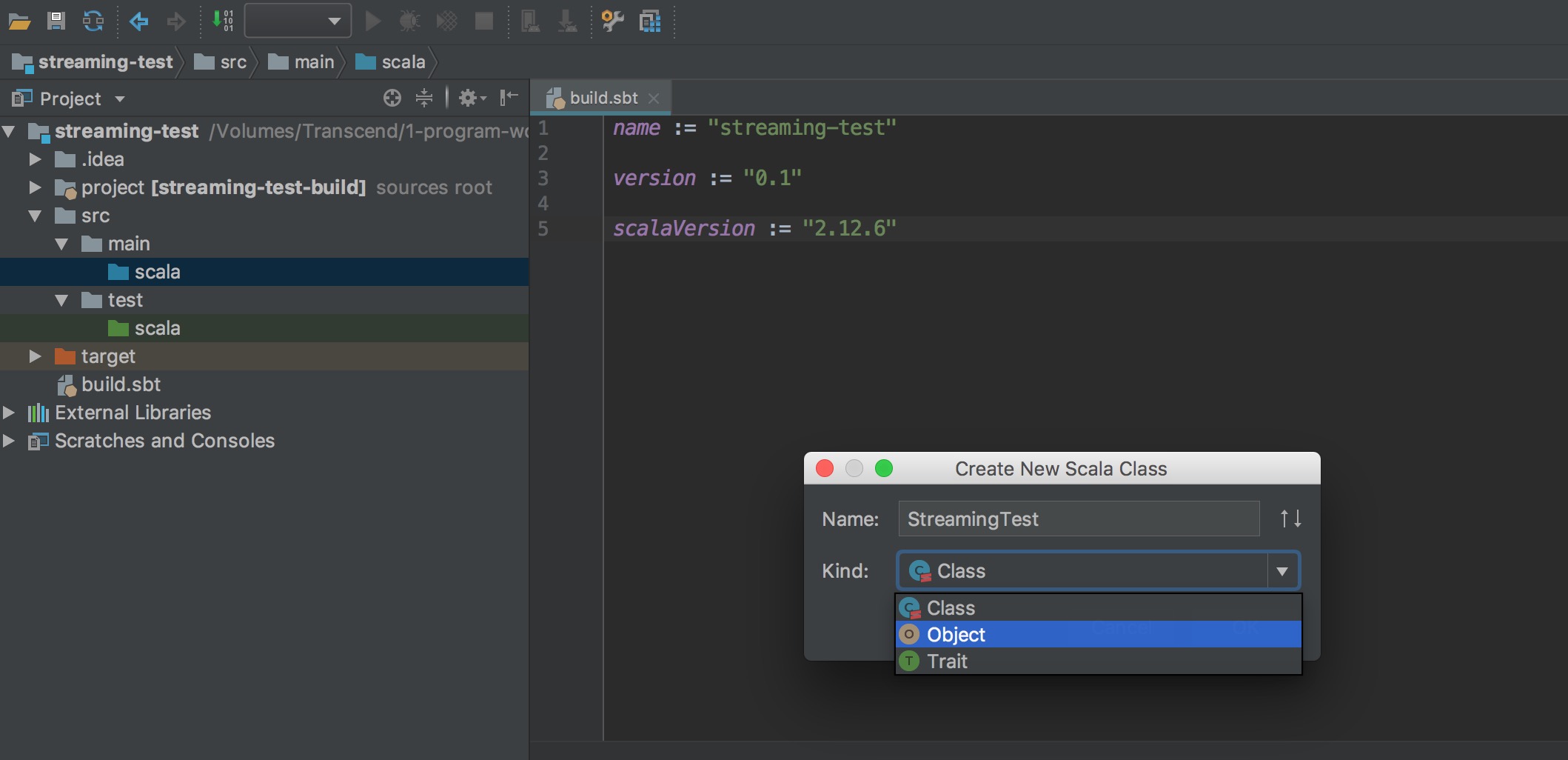
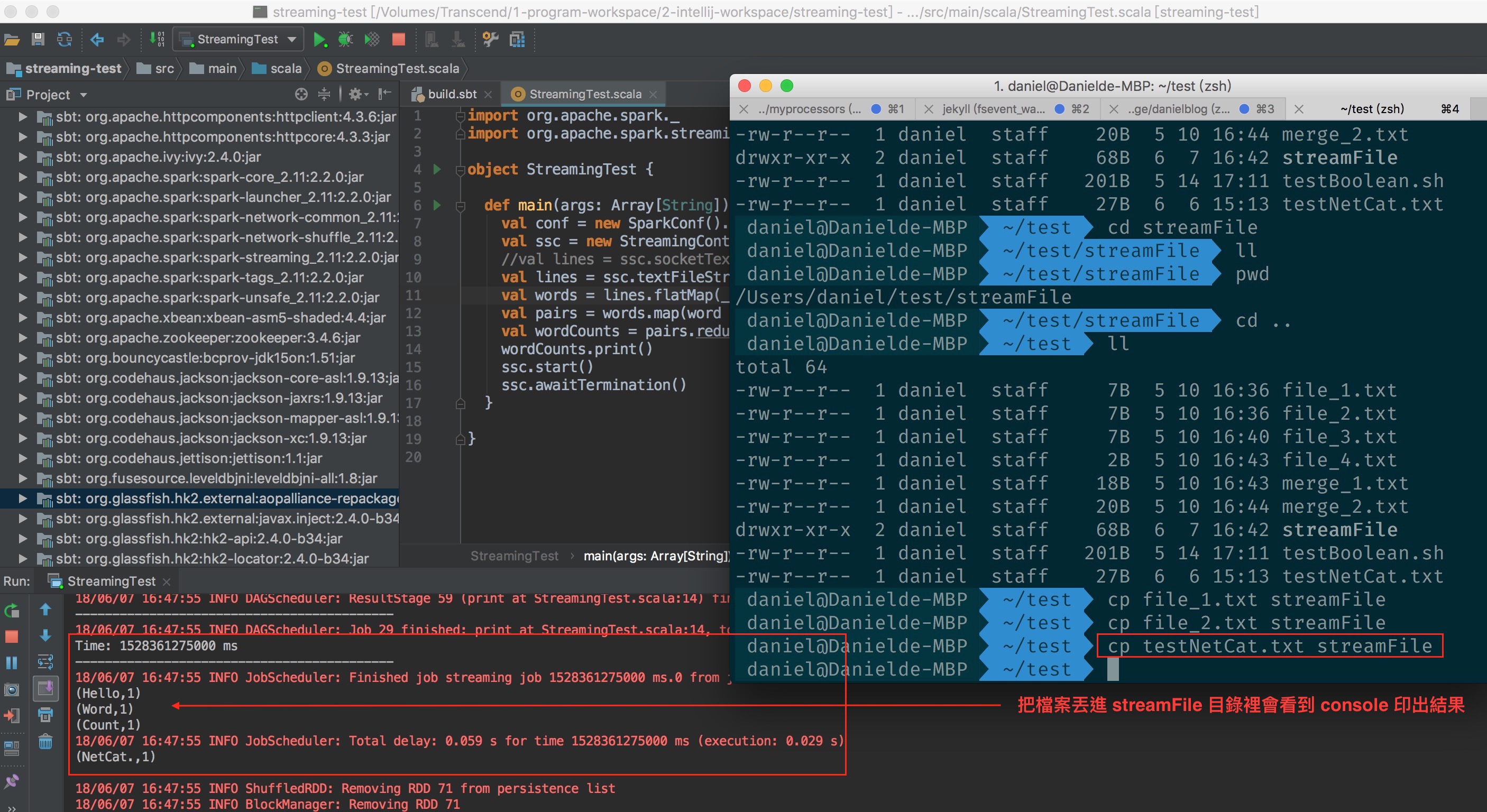
寫一個測試程式 StreamingTest
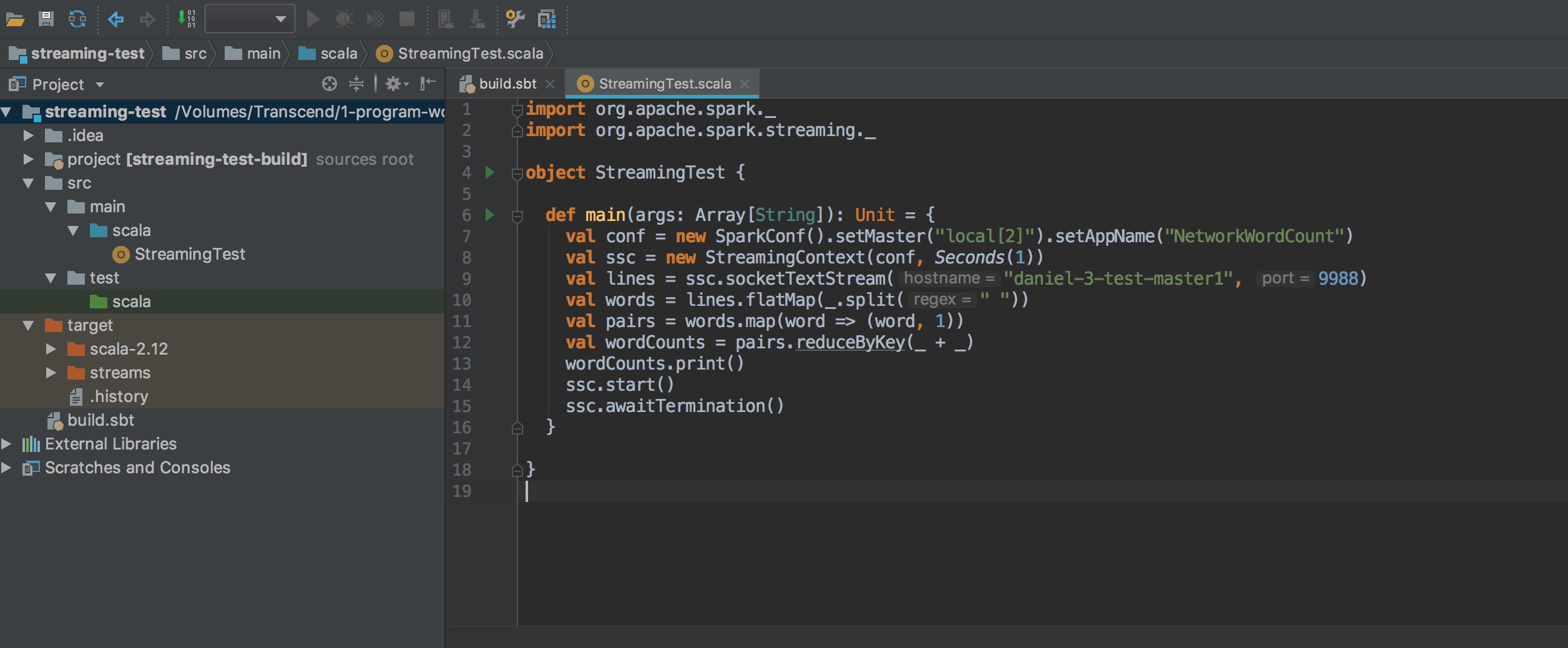
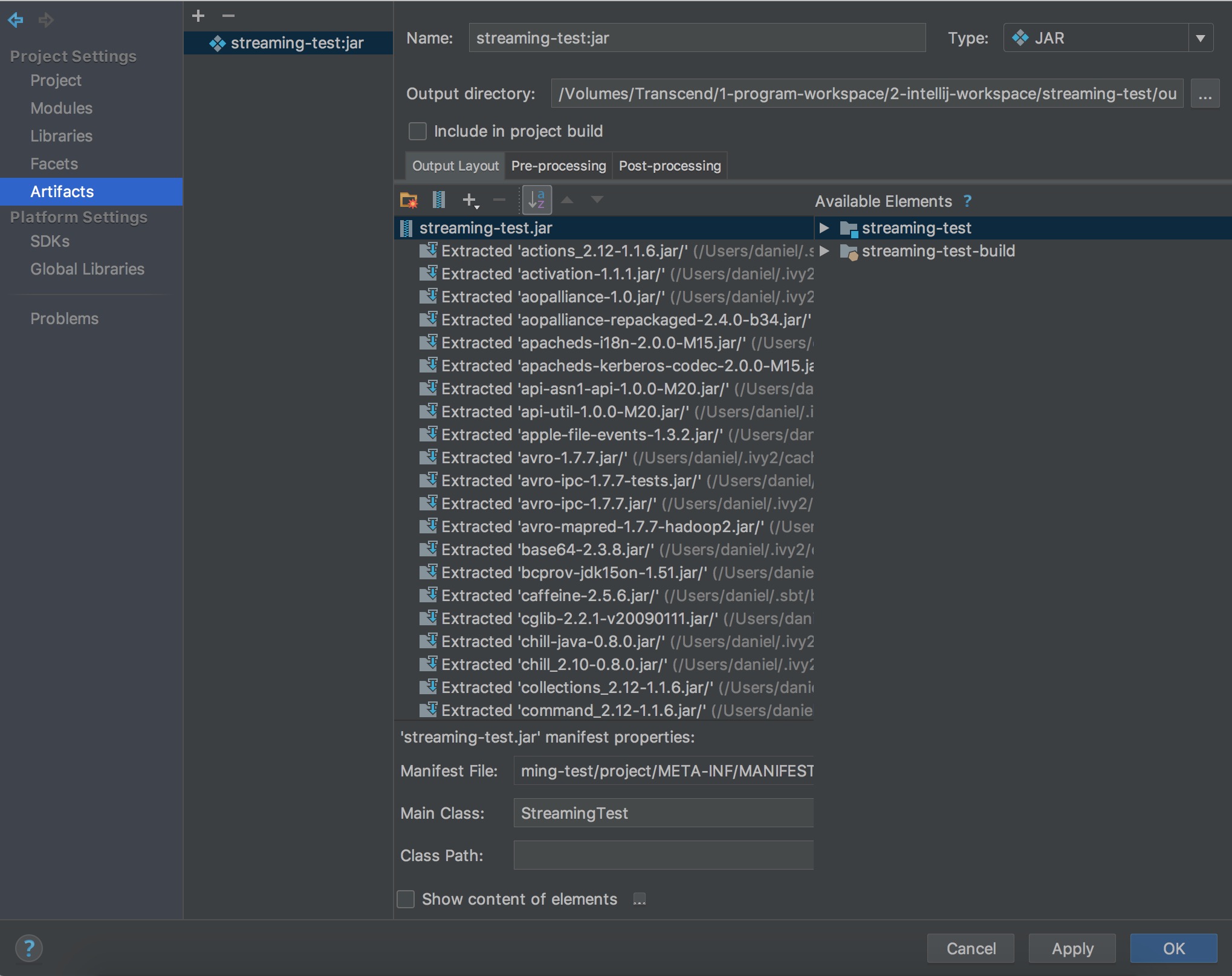
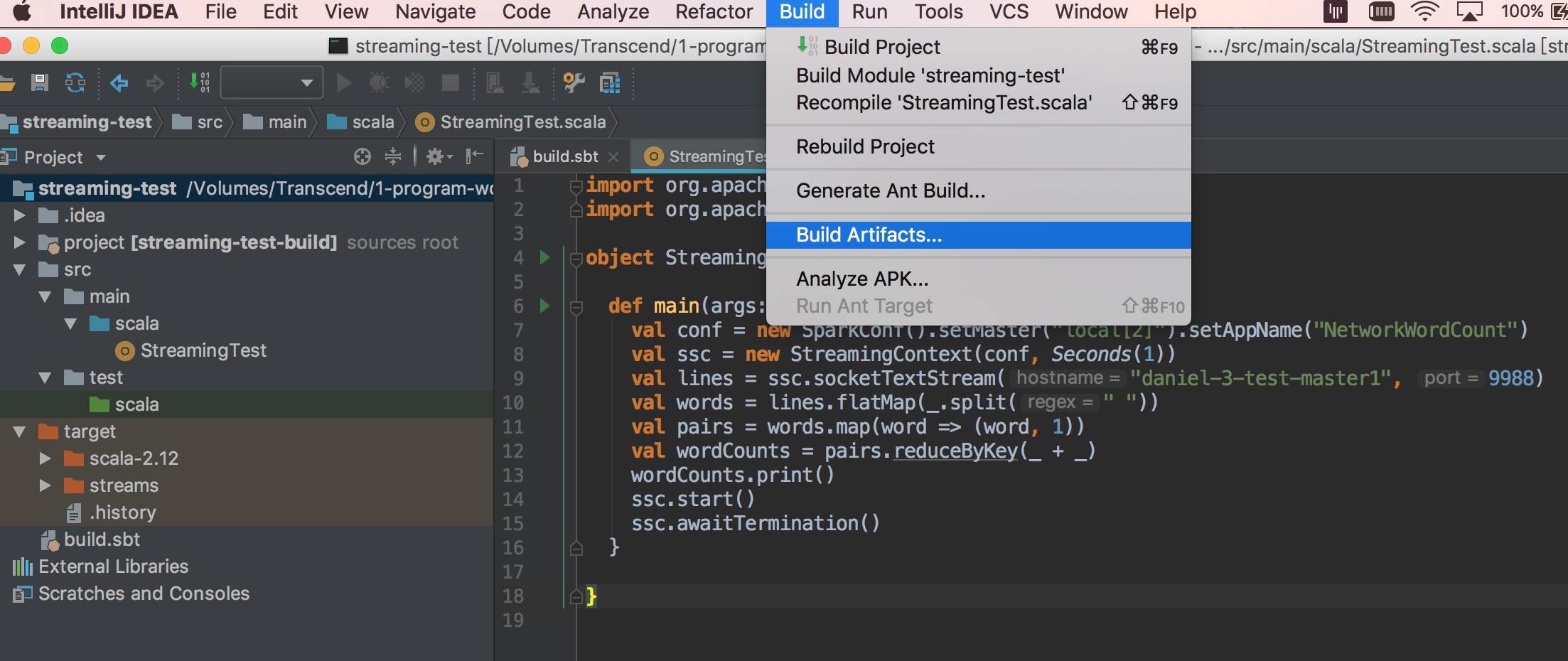
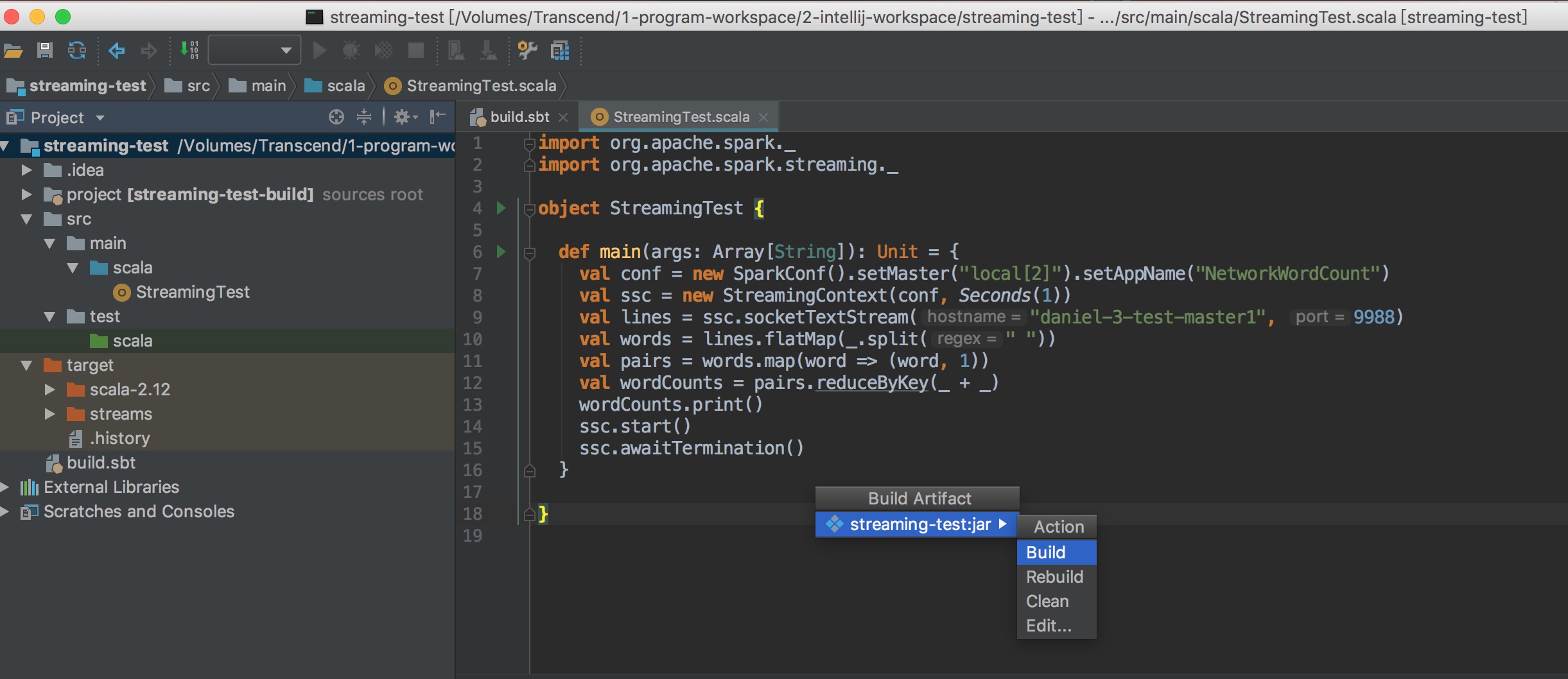
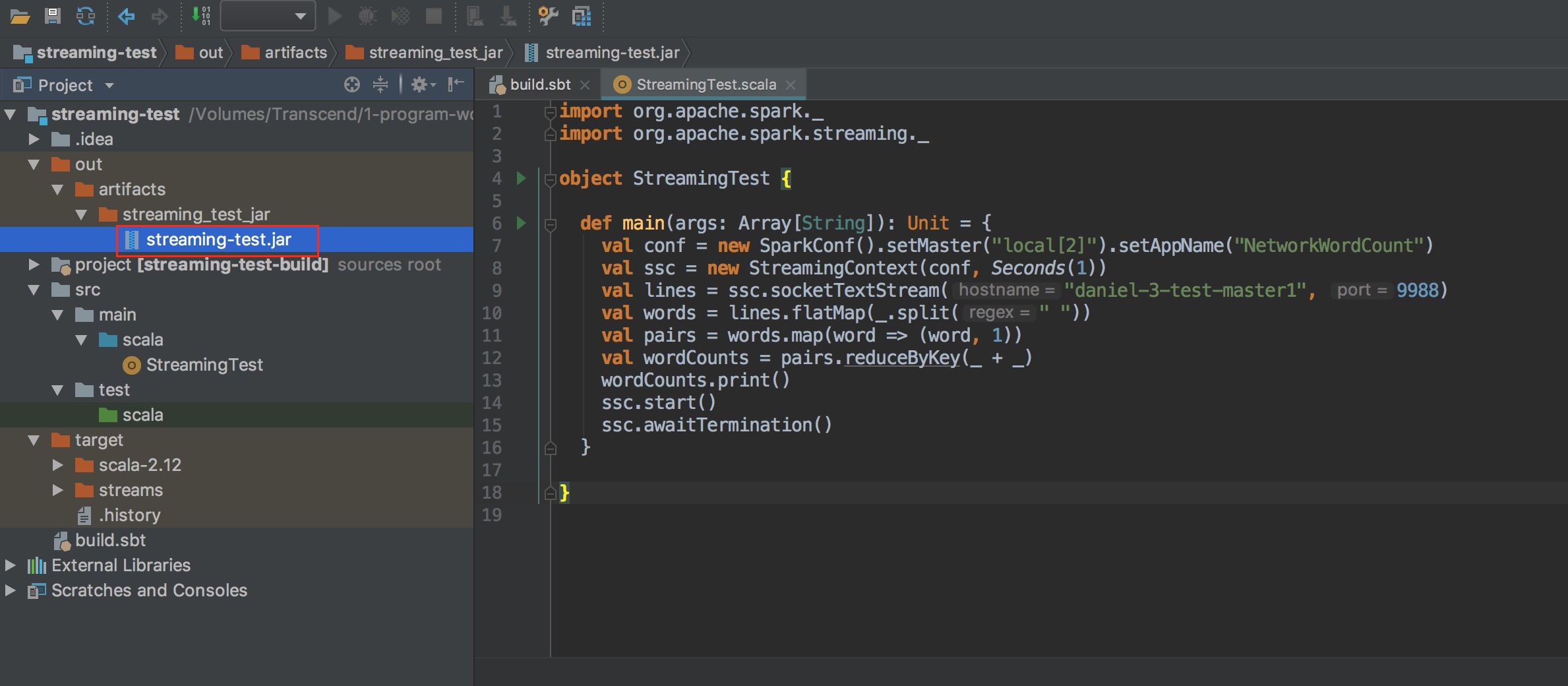
使用 intelliJ build jar
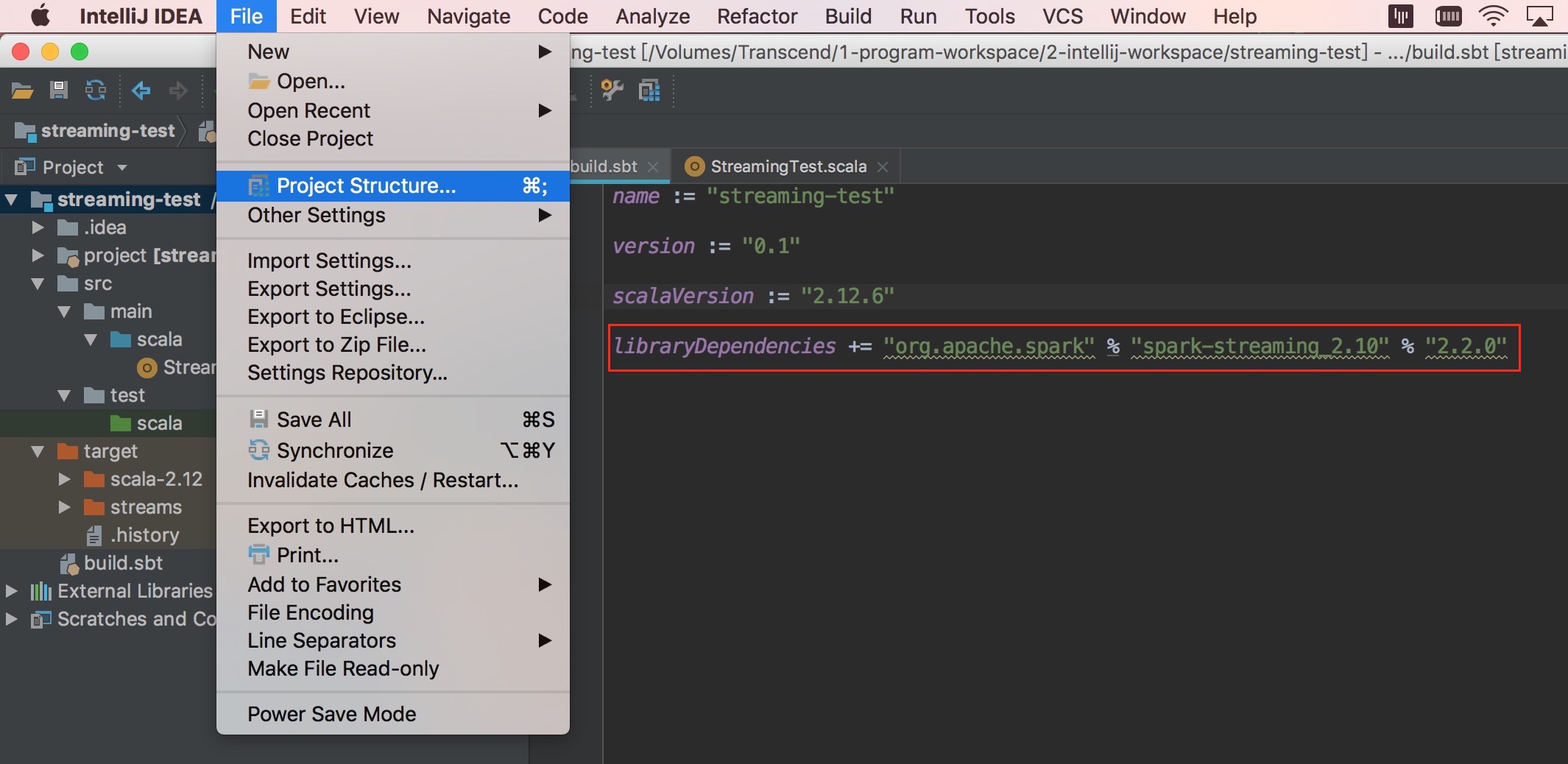
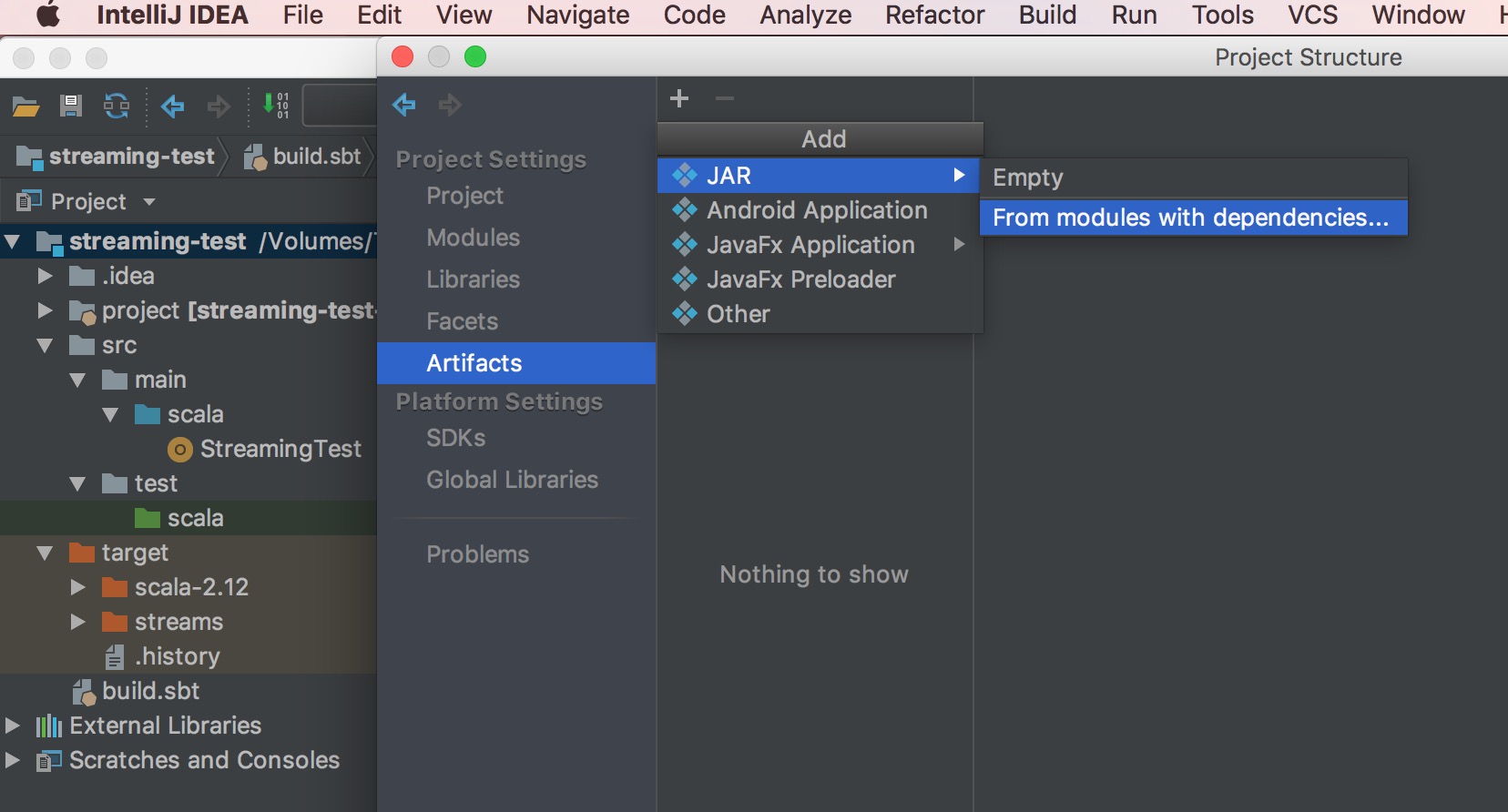
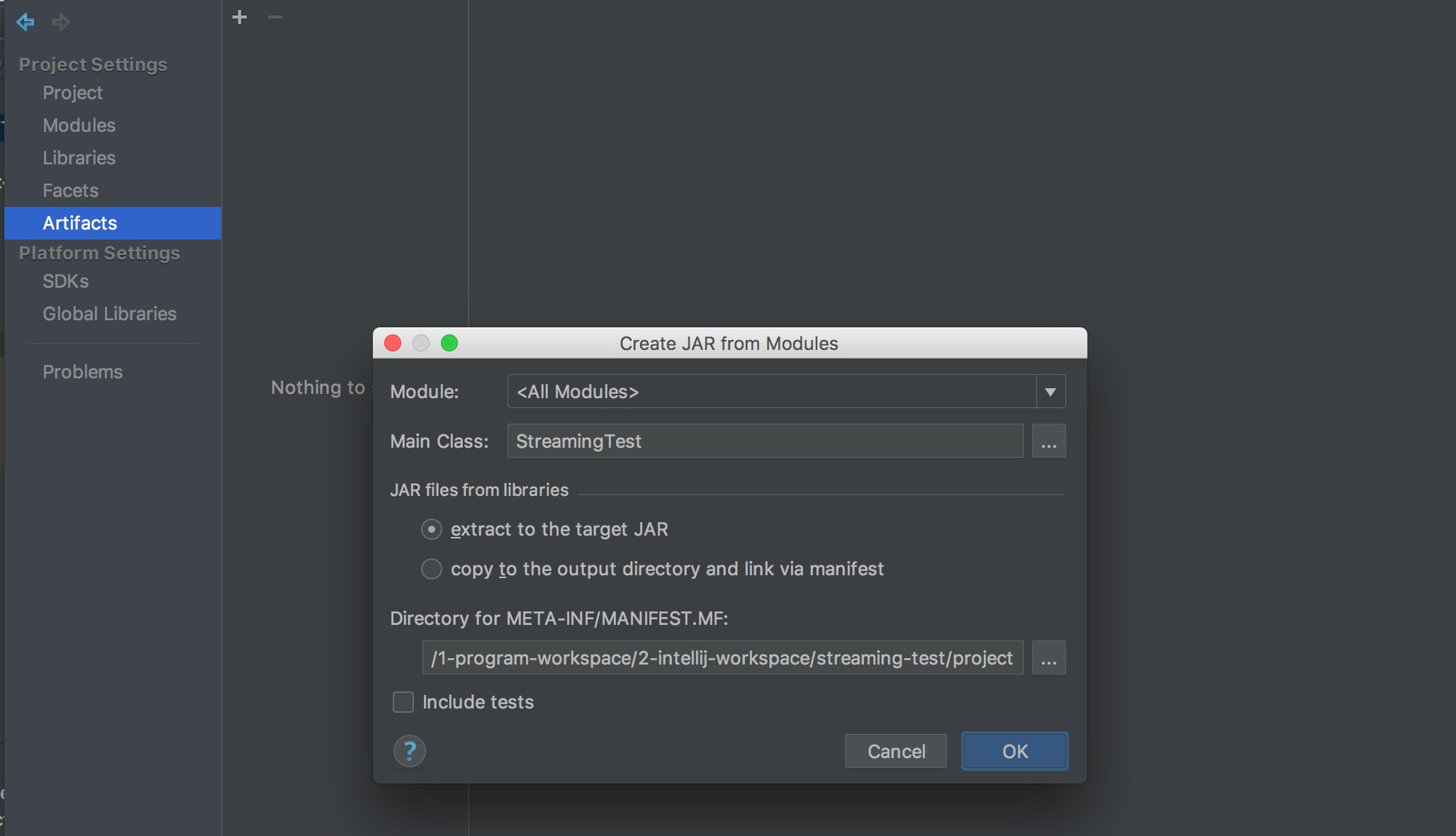
啟動一個 netcat

先直接 run main function 測試看看
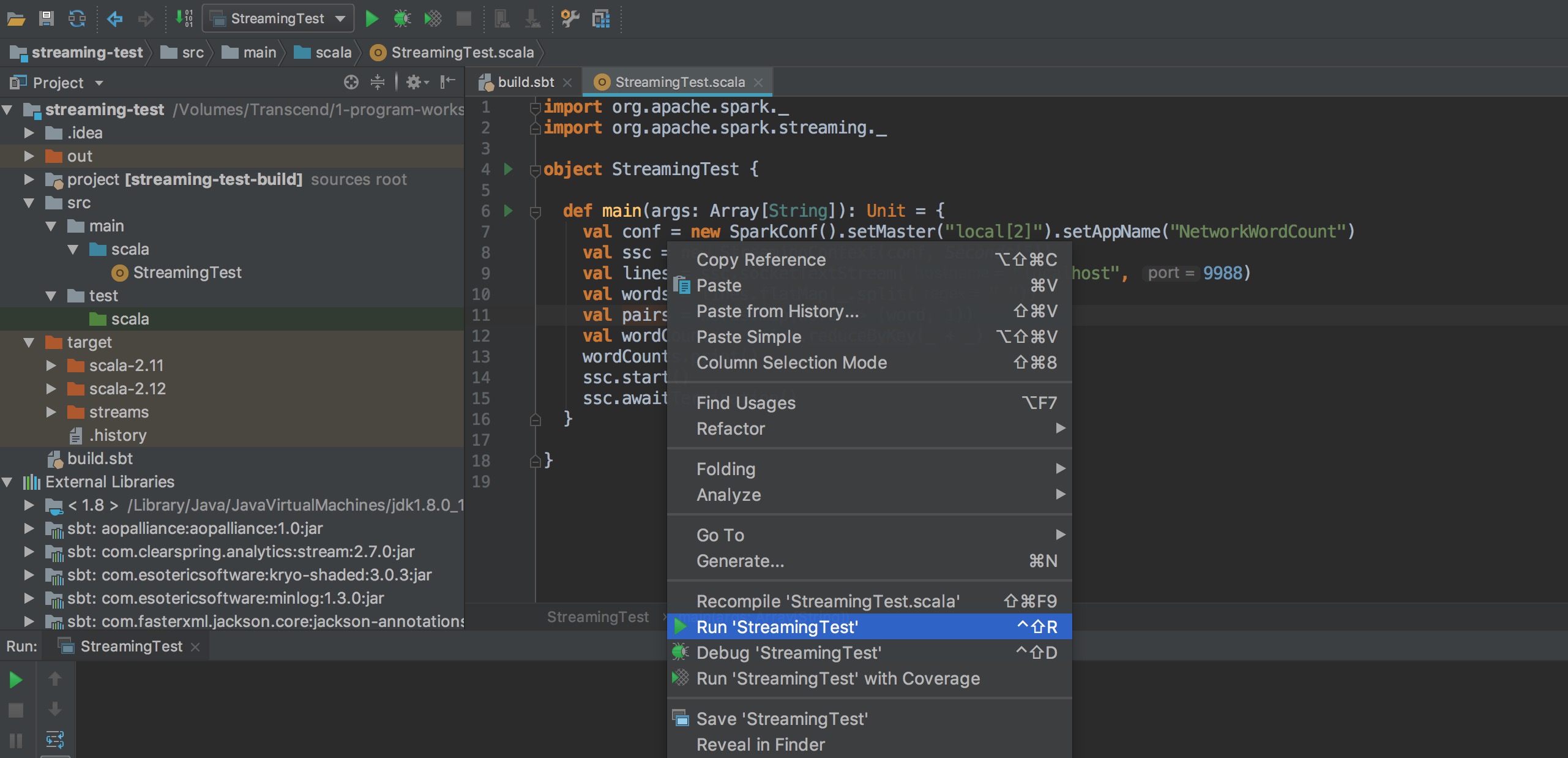
出現下列錯誤訊息
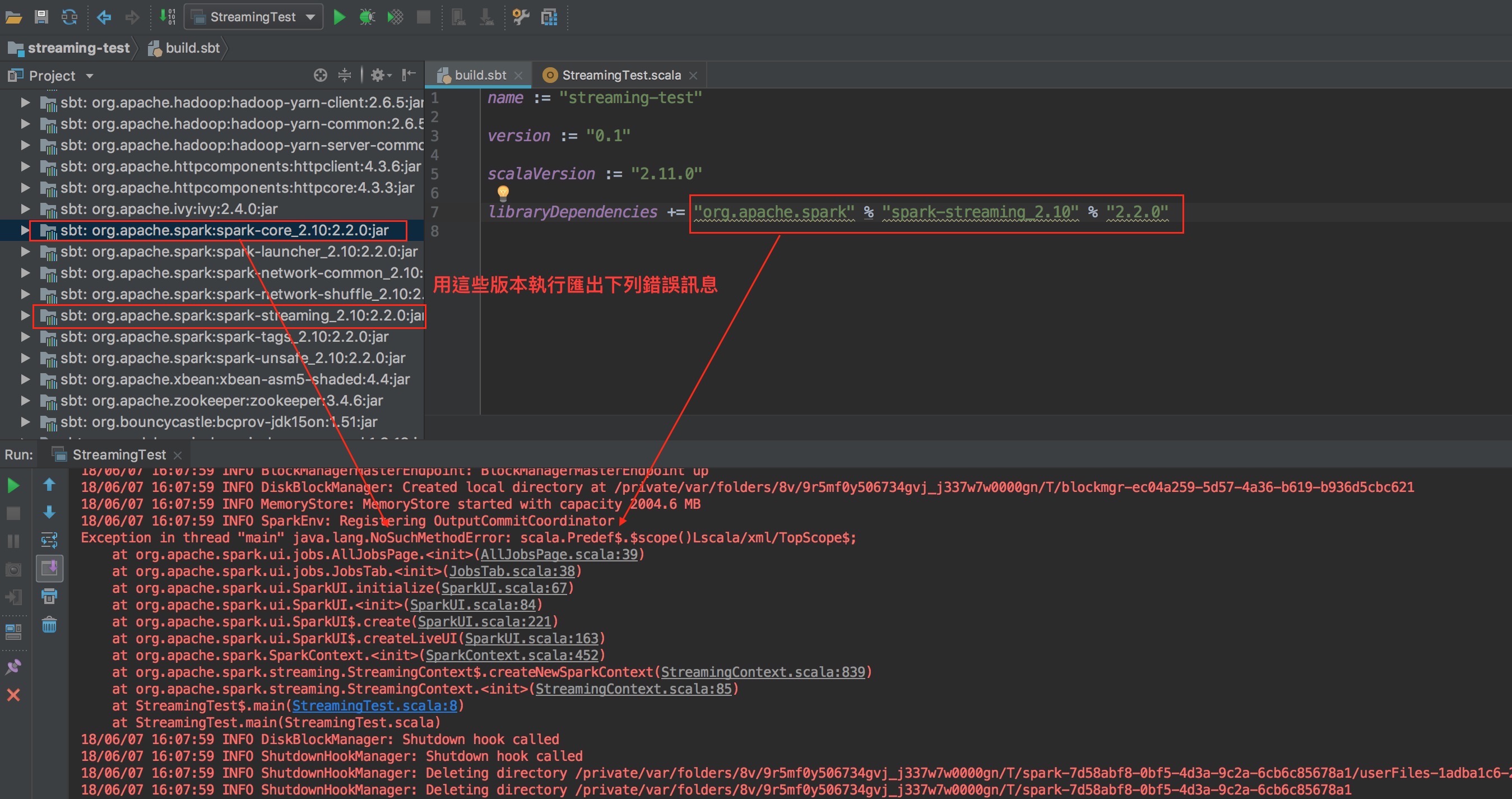
修改 sbt 檔,從 2.10 版變成 2.11
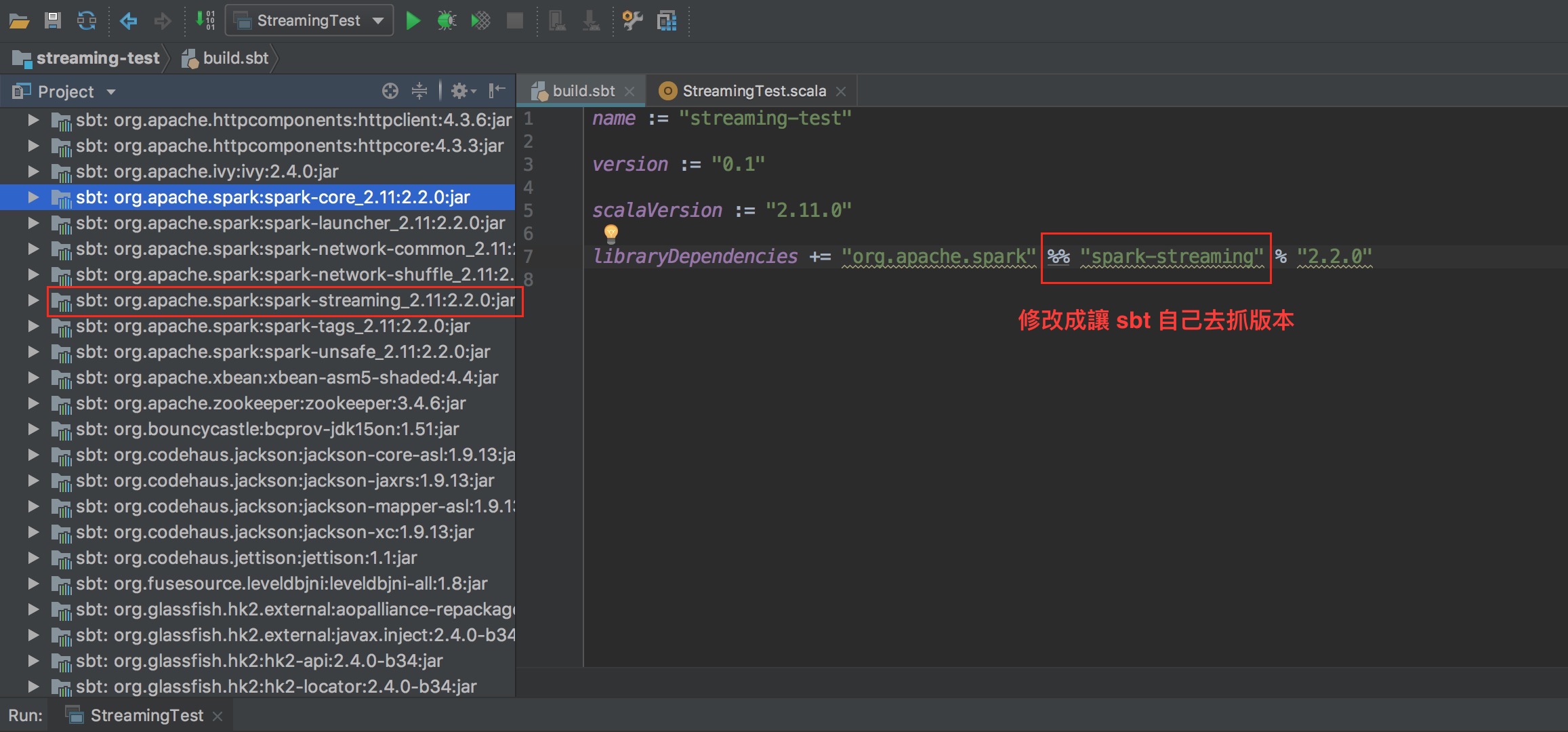
測試執行成功
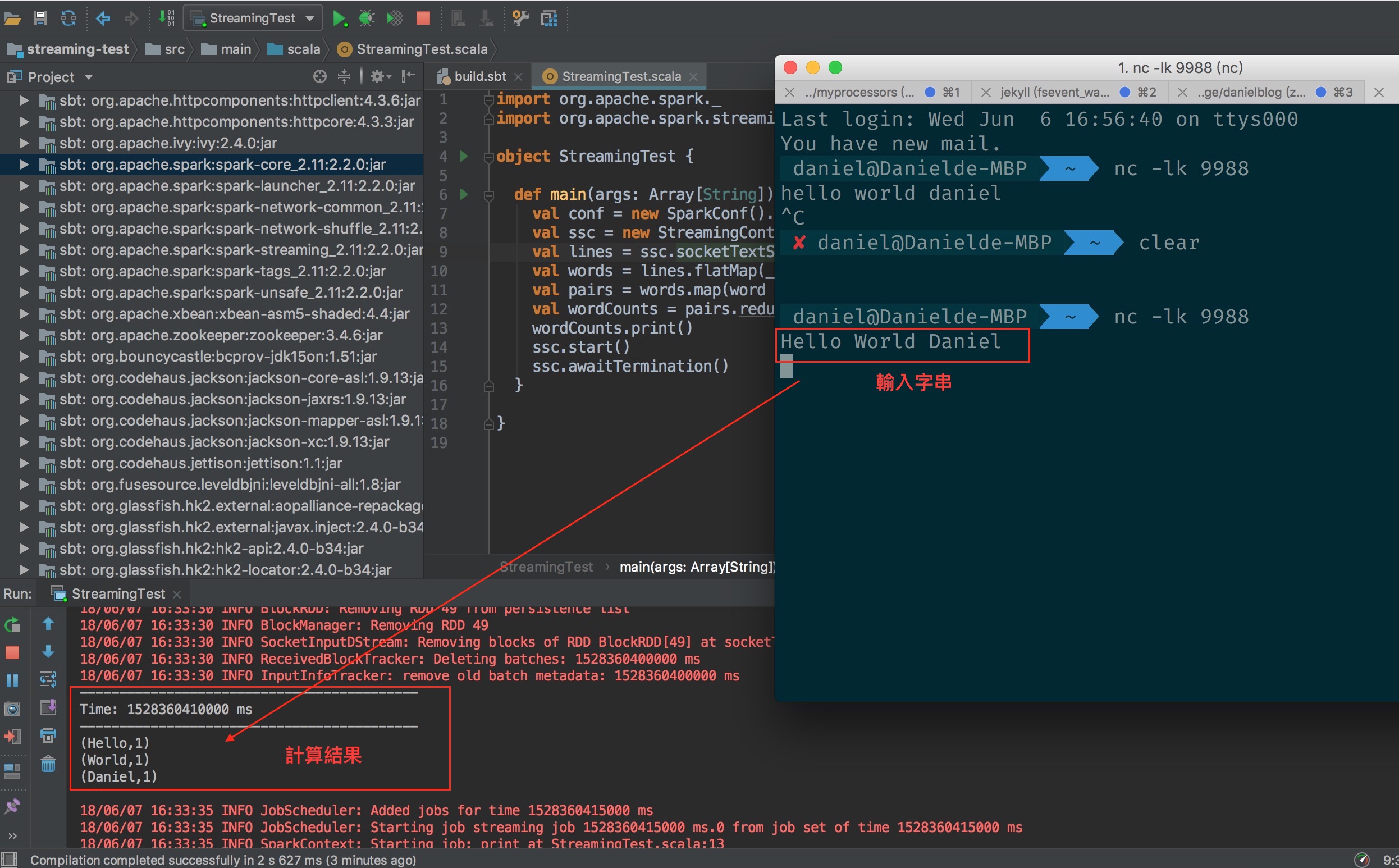
接著 demo 讓 spark-streaming 從某個目錄抓取檔案內容處理
在本機建立一個目錄路徑為 /Users/daniel/test/streamFile
修改程式
將原來的 ssc.socketTextStream 改成 ssc.textFileStream
import org.apache.spark._
import org.apache.spark.streaming._
object StreamingTest {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
val ssc = new StreamingContext(conf, Seconds(5))
//val lines = ssc.socketTextStream("localhost", 9988)
val lines = ssc.textFileStream("file:///Users/daniel/test/streamFile")
val words = lines.flatMap(_.split(" "))
val pairs = words.map(word => (word, 1))
val wordCounts = pairs.reduceByKey(_ + _)
wordCounts.print()
ssc.start()
ssc.awaitTermination()
}
}
測試執行成功
使用 spark2-submit 測試
- 流程圖
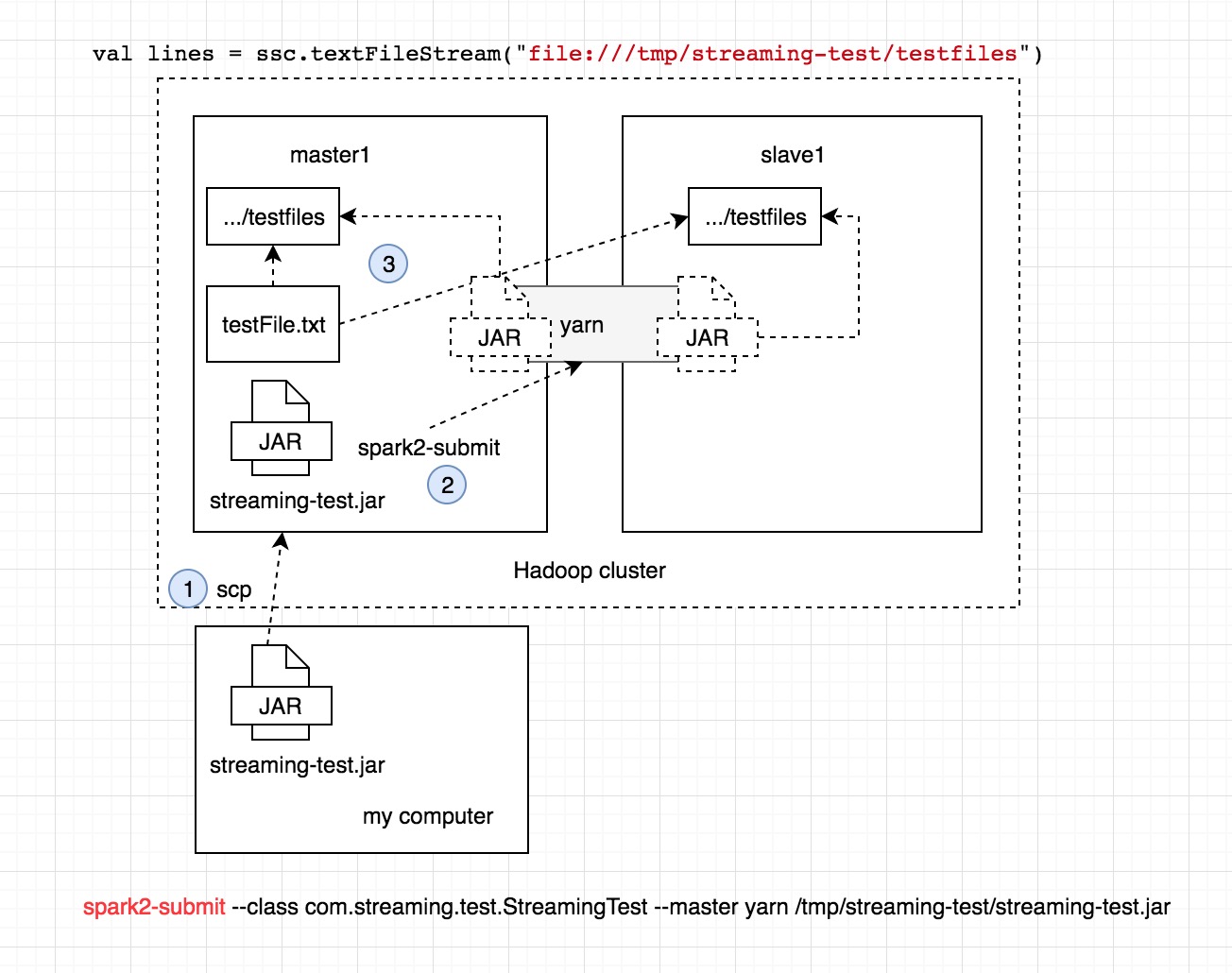
1.先把 compiler 好的 jar 丟到 master1 上面
scp streaming-test.jar root@192.168.61.105:/tmp/streaming-test
2.在使用 spark2-submit 把 spark job 送到 yarn 上執行
spark2-submit --class com.streaming.test.StreamingTest --master yarn /tmp/streaming-test/streaming-test.jar
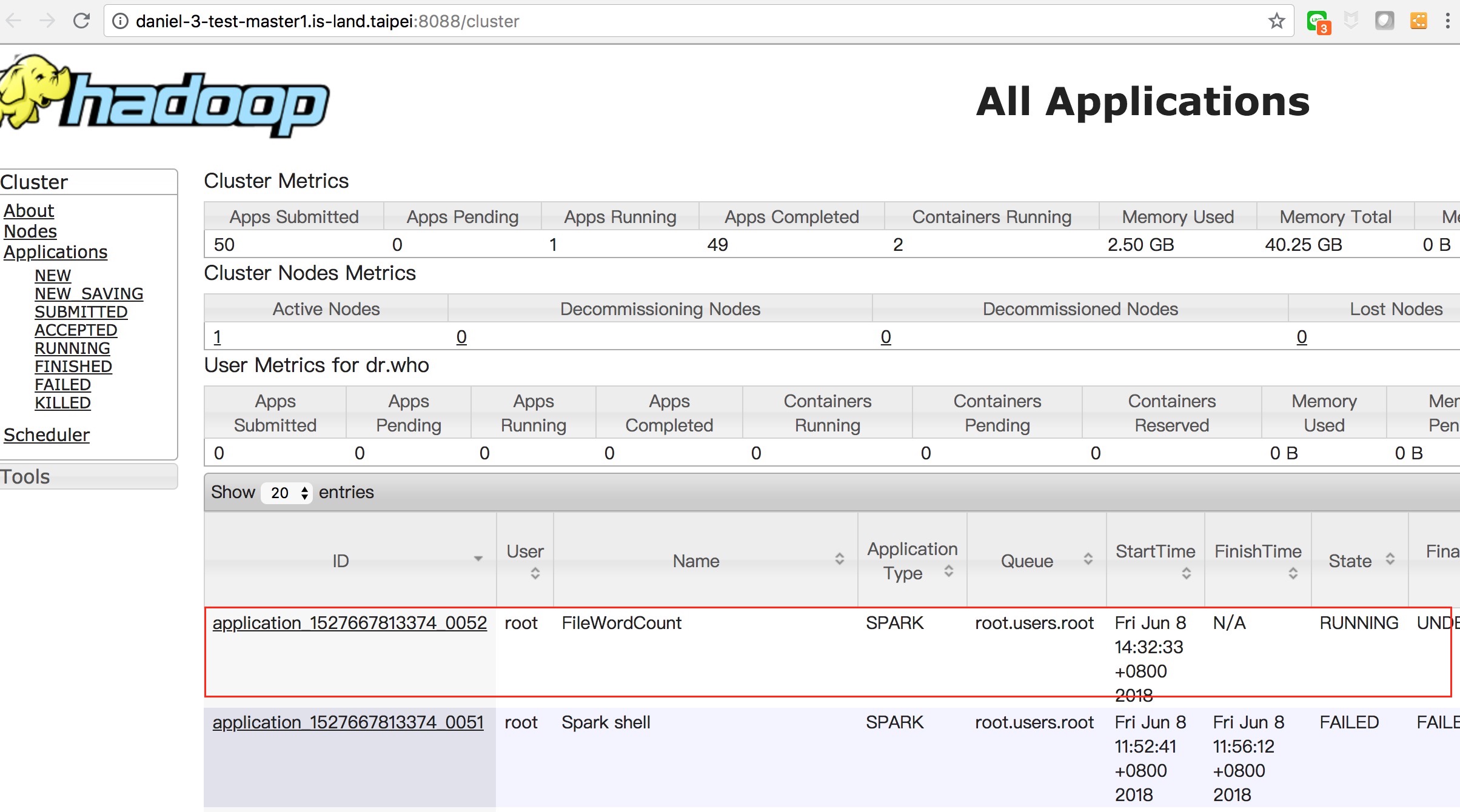
- 成功後會再 yarn 上看到執行的 job
3.再把檔案(testFile.txt)丟到該目錄底下(/tmp/streaming-test/testfiles)
- 但 master1 及 slave 1 都要有該檔案及目錄,因為是分散式處理的關係
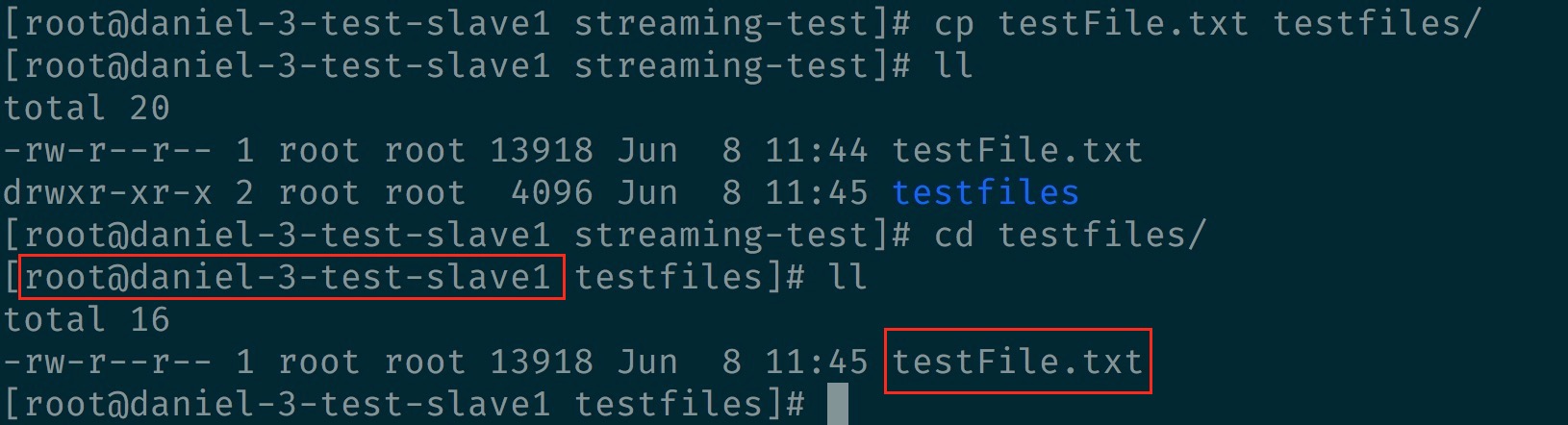

會在 master1 上看到執行結果